Demystifying Softmax Selection Policy in Deep Reinforcement Learning
Deep Reinforcement Learning (DRL) has emerged as a powerful and innovative approach in Artificial Intelligence (AI), enabling machines to learn from their interactions with the environment and make informed decisions. At the heart of DRL lies the Softmax Selection Policy, a crucial component that optimizes decision-making processes. This article aims to shed light on the Softmax Selection Policy and its significance in the realm of Deep Reinforcement Learning.

Click Image to Find Quantum Products
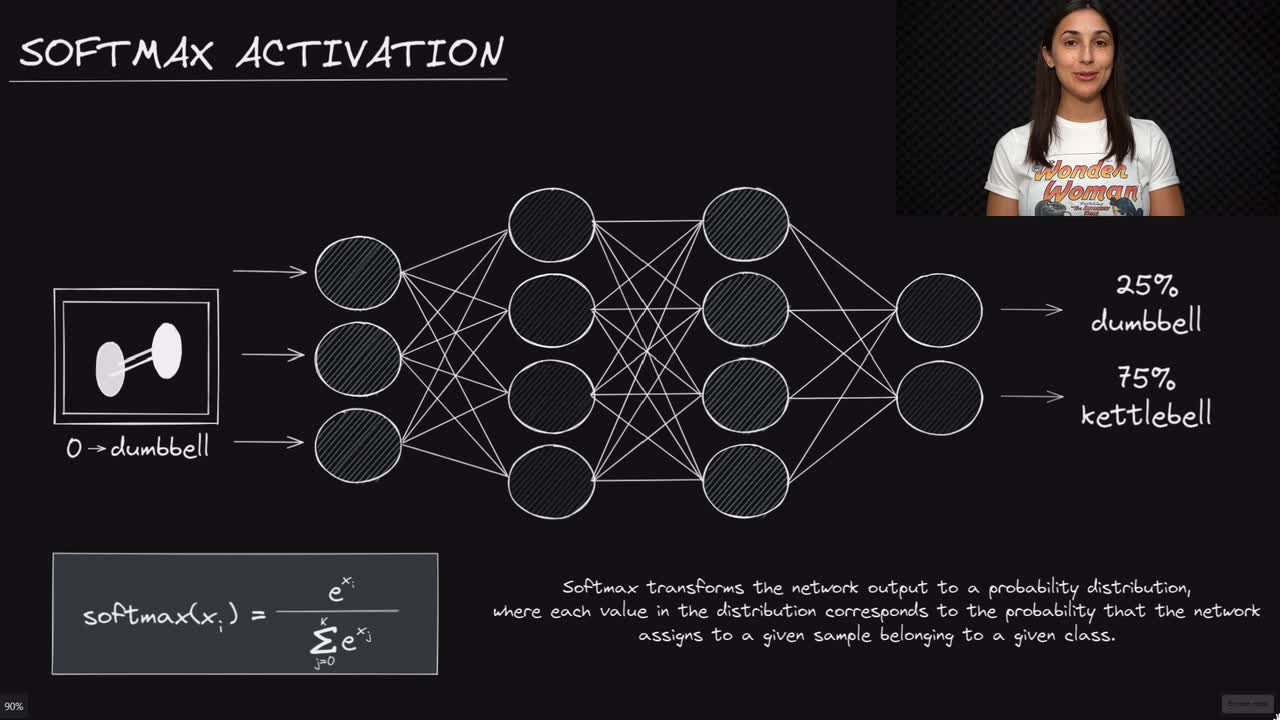
Reinforcement Learning (RL) revolves around an agent and its environment. The agent takes actions based on its current state, and the environment responds with rewards or penalties. The objective of RL is to maximize the cumulative reward over time. In DRL, deep neural networks are employed to approximate the value function, which estimates the expected return for each state-action pair. The Softmax Selection Policy plays a pivotal role in this process, transforming these raw value outputs into probabilities, thereby facilitating more informed decisions.
How Does Softmax Selection Policy Work in Deep Reinforcement Learning?
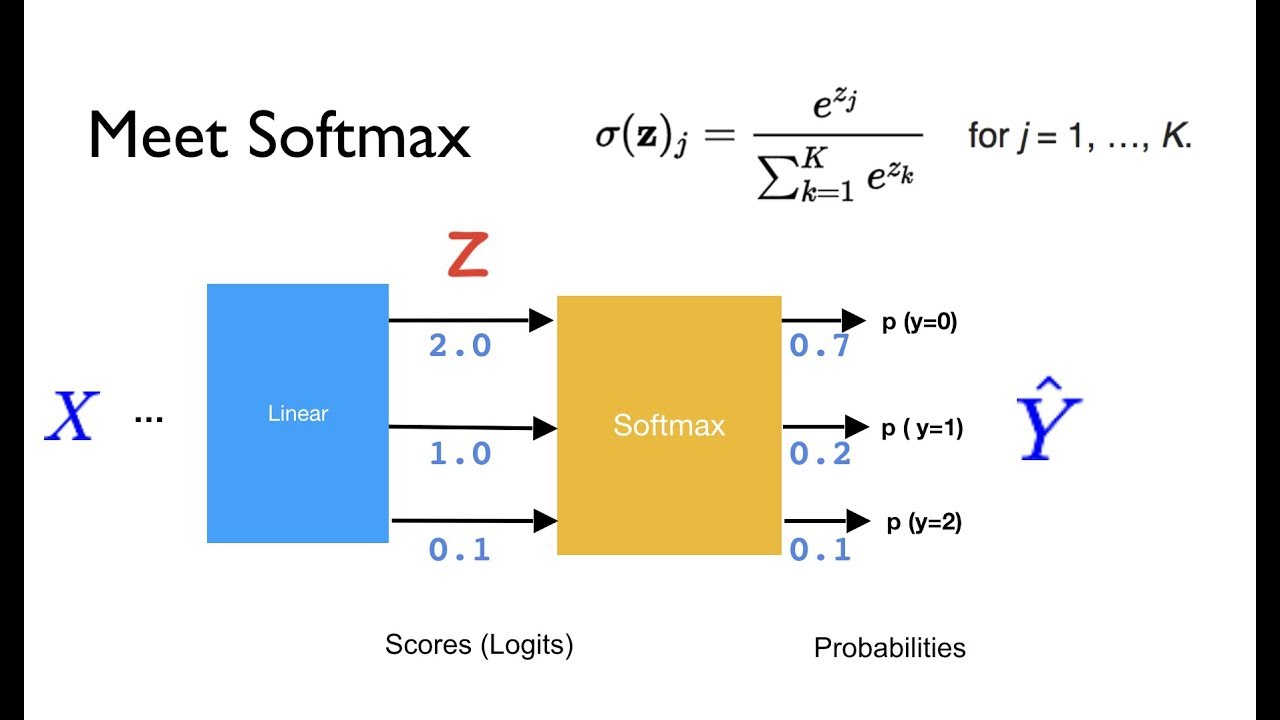
The Softmax Selection Policy is a key element in Deep Reinforcement Learning, responsible for converting raw value outputs into probabilities. This transformation enables more informed decision-making processes by selecting actions with higher expected returns. The Softmax function, which underpins this policy, can be defined as follows:
softmax(x)i = exp(xi) / Σexp(xj)
In this equation, x represents a vector of raw value outputs, and i and j denote individual elements within that vector. The Softmax function calculates the probability of selecting each action based on its associated raw value output. The exponential function ensures that all values are positive, and the denominator normalizes the probabilities so that they sum up to 1.
To illustrate the workings of the Softmax Selection Policy, consider an example where an agent has three possible actions, each with a raw value output as follows: action_1 = 5, action_2 = 10, and action_3 = 8. Applying the Softmax function, we get the following probabilities:
softmax(action_1) ≈ 0.073
softmax(action_2) ≈ 0.245
softmax(action_3) ≈ 0.176
As evident from these probabilities, the Softmax Selection Policy favors actions with higher raw value outputs, thereby increasing the likelihood of selecting the optimal action. This behavior is crucial for effective decision-making in Deep Reinforcement Learning environments.
Comparing Softmax Selection Policy with Alternative Approaches
In Deep Reinforcement Learning, various selection policies and strategies exist to optimize decision-making processes. Among these, the Softmax Selection Policy has gained popularity due to its ability to transform raw value outputs into probabilities, thereby facilitating more informed decisions. Here, we compare the Softmax Selection Policy with alternative approaches, highlighting its advantages.
ε-greedy is a commonly used selection policy that balances exploration and exploitation. It selects the action with the highest estimated value most of the time but also allows random action selection with a small probability (ε) to ensure exploration. While ε-greedy is simple and effective, it may struggle to balance exploration and exploitation optimally, especially in complex environments. In contrast, the Softmax Selection Policy provides a more nuanced approach by considering the relative differences between action values, which can lead to better performance in some scenarios.
Another alternative approach is the Boltzmann exploration strategy, which is closely related to the Softmax Selection Policy. The Boltzmann strategy calculates probabilities based on the raw value outputs using the following formula:
probability(action) ∝ exp(Q(action) / temperature)
Here, the temperature parameter controls the randomness of the action selection process. As the temperature decreases, the Boltzmann strategy becomes more deterministic, focusing on actions with the highest values. The Softmax Selection Policy can be seen as a special case of the Boltzmann strategy with a temperature of 1. While the Boltzmann strategy offers more flexibility in controlling the exploration-exploitation trade-off, the Softmax Selection Policy provides a more straightforward and intuitive approach, making it a popular choice for many Deep Reinforcement Learning applications.
| Selection Policy | Advantages | Disadvantages |
|---|---|---|
| Softmax Selection Policy | Considers relative differences between action values, intuitive and straightforward. | Limited control over exploration-exploitation trade-off. |
| ε-greedy | Simple and effective, easy to implement. | May struggle to balance exploration and exploitation optimally. |
| Boltzmann Strategy | Flexible control over exploration-exploitation trade-off. | More complex and less intuitive than the Softmax Selection Policy. |
Implementing Softmax Selection Policy in Deep Reinforcement Learning Algorithms
To harness the power of the Softmax Selection Policy in Deep Reinforcement Learning, it’s essential to understand how to incorporate it into popular algorithms such as Q-Learning and Deep Q-Networks (DQNs). Here, we provide a step-by-step guide on implementing the Softmax Selection Policy in these algorithms.
Q-Learning with Softmax Selection Policy
Q-Learning is a value-based Reinforcement Learning algorithm that aims to learn the optimal action-value function. To implement the Softmax Selection Policy in Q-Learning, follow these steps:
-
- Initialize the Q-table with zeros or small random values.
- For each episode, perform the following steps:
- Initialize the state.
- While the episode is not terminated, perform the following steps:
- Calculate the Q-values for all possible actions using the current Q-table.
- Apply the Softmax function to the Q-values to obtain probabilities.
- Sample an action from the probability distribution.
- Take the action, observe the reward, and transition to the new state.
- Update the Q-value for the state-action pair using the Q-learning update rule:
Q(s, a) ← Q(s, a) + α [r + γ max\_a' Q(s', a') - Q(s, a)]
Deep Q-Networks with Softmax Selection Policy
Deep Q-Networks (DQNs) are an extension of Q-Learning that use a deep neural network to approximate the action-value function. To incorporate the Softmax Selection Policy in DQNs, follow these steps:
- Initialize the DQN with random weights.
- For each episode, perform the following steps:
- Initialize the state.
- While the episode is not terminated, perform the following steps:
- Calculate the Q-values for all possible actions using the DQN.
- Apply the Softmax function to the Q-values to obtain probabilities.
- Sample an action from the probability distribution.
- Take the action, observe the reward


-
Optimizing Softmax Selection Policy for Improved Performance
To maximize the potential of the Softmax Selection Policy in Deep Reinforcement Learning, it’s essential to fine-tune its performance using techniques such as temperature adjustment and entropy regularization. These methods can significantly enhance the overall performance of Deep Reinforcement Learning models.
Temperature Adjustment
The temperature parameter in the Softmax function controls the randomness of action selection. A high temperature value results in a more uniform probability distribution, promoting exploration, while a low temperature value leads to a more deterministic distribution, favoring exploitation. Adjusting the temperature during learning can balance exploration and exploitation effectively.
A common approach is to start with a high temperature, allowing the model to explore various actions in the early stages of learning. As learning progresses, decrease the temperature gradually, encouraging the model to focus on actions with higher expected rewards. This annealing process can be implemented using various schedules, such as linear or exponential decay.
Entropy Regularization
Entropy Regularization is a technique used to encourage exploration in Reinforcement Learning by adding an entropy term to the loss function. Entropy measures the randomness or uncertainty of the probability distribution over actions. By maximizing entropy, the model is incentivized to maintain a diverse probability distribution, promoting exploration.
Incorporating entropy regularization into the Softmax Selection Policy can be achieved by adding an entropy term to the loss function:
L(θ) = E_t[r_t + γ * max_a' Q(s', a'; θ') - Q(s_t, a_t; θ)] - λ * H(π(· | s_t; θ))Here,
H(π(· | s\_t; θ))represents the entropy of the policy, andλis the regularization coefficient that controls the trade-off between exploration and exploitation. By adjusting the value ofλ, you can control the level of exploration during learning.Optimizing the Softmax Selection Policy using temperature adjustment and entropy regularization can significantly improve the performance of Deep Reinforcement Learning models. These techniques enable the model to balance exploration and exploitation effectively, leading to better decision-making and more informed actions.
Real-World Applications of Softmax Selection Policy in Deep Reinforcement Learning
The Softmax Selection Policy plays a crucial role in optimizing decision-making processes in various real-world applications of Deep Reinforcement Learning. Its ability to transform raw value outputs into probabilities enables more informed actions in complex environments, making it an essential tool in several domains, such as robotics, gaming, and autonomous systems.
Robotics
In robotics, the Softmax Selection Policy can be used to optimize control policies for robotic manipulation tasks, such as grasping and assembly. By converting value outputs into probabilities, the policy can balance exploration and exploitation, allowing robots to learn optimal actions while adapting to new situations.
Gaming
The Softmax Selection Policy has been successfully applied to various gaming scenarios, including board games and video games. For instance, in the game of Go, the Softmax Selection Policy can be used to select moves based on their expected values, enabling the agent to learn and adapt its strategy over time.
Autonomous Systems
Autonomous systems, such as self-driving cars, can benefit from the Softmax Selection Policy by using it to make informed decisions in complex, dynamic environments. By considering the expected values of different actions, the policy can help autonomous systems navigate roads, avoid obstacles, and make safe driving decisions.
Incorporating the Softmax Selection Policy into real-world applications of Deep Reinforcement Learning can lead to significant improvements in decision-making and problem-solving capabilities. Its ability to balance exploration and exploitation enables more efficient learning and adaptation in complex environments, making it an invaluable tool for AI researchers and practitioners alike.
By understanding and applying the Softmax Selection Policy, researchers and practitioners can unlock the full potential of Deep Reinforcement Learning in various real-world applications, ultimately driving innovation and progress in the field of Artificial Intelligence.
Future Perspectives and Challenges in Softmax Selection Policy Research
The Softmax Selection Policy has proven to be an essential component in Deep Reinforcement Learning, demonstrating its effectiveness in various applications. However, there are still emerging trends, challenges, and opportunities for improvement in this field. Addressing these issues can lead to better performance, generalization, and robustness in Deep Reinforcement Learning models.
Multi-Agent Scenarios
In multi-agent scenarios, the Softmax Selection Policy can be extended to account for interactions between multiple agents. This extension can lead to new challenges, such as dealing with non-stationary environments and developing mechanisms to handle cooperative and competitive behaviors. Future research can focus on developing Softmax Selection Policies tailored for multi-agent systems, enabling more efficient learning and decision-making in such environments.
Generalization and Robustness
Generalization and robustness are critical aspects of Deep Reinforcement Learning models. The Softmax Selection Policy can be improved to better handle novel situations and maintain performance in the presence of noise, adversarial attacks, or changes in the environment. Future research can explore techniques for enhancing the generalization and robustness of the Softmax Selection Policy, ensuring that models can adapt and perform well in a wide range of scenarios.
Scalability and Efficiency
Scalability and efficiency are essential for real-world applications of Deep Reinforcement Learning. As problems become larger and more complex, there is a need for Softmax Selection Policies that can handle high-dimensional state and action spaces without compromising performance. Future research can focus on developing scalable and efficient Softmax Selection Policies, possibly by incorporating advances in deep learning architectures and optimization techniques.
Explainability and Interpretability
Explainability and interpretability are becoming increasingly important in AI applications, as they enable users to understand and trust the decision-making processes of models. The Softmax Selection Policy can be enhanced to provide more transparent insights into the decision-making process, enabling users to better understand the rationale behind the selected actions. Future research can explore methods for improving the explainability and interpretability of the Softmax Selection Policy, ensuring that models can be effectively deployed in safety-critical applications.
By addressing these challenges and opportunities, researchers can contribute to the development of more advanced, efficient, and reliable Softmax Selection Policies in Deep Reinforcement Learning. These advancements can have a significant impact on the future of AI, enabling more informed decision-making and problem-solving capabilities in various real-world applications.
Conclusion: The Power of Softmax Selection Policy in Deep Reinforcement Learning
The Softmax Selection Policy has emerged as a vital component in Deep Reinforcement Learning, playing a significant role in optimizing decision-making processes and enabling more informed choices. Its ability to transform raw value outputs into probabilities has proven to be an effective strategy in various applications, from robotics and gaming to autonomous systems.
As Deep Reinforcement Learning continues to evolve and expand, the Softmax Selection Policy remains a cornerstone in the development of advanced AI models. Its potential impact on the future of Artificial Intelligence is immense, as it contributes to more efficient, adaptive, and reliable decision-making processes.
Exploring and applying the Softmax Selection Policy in Deep Reinforcement Learning projects and research can lead to significant breakthroughs and innovations. By understanding its mechanics, advantages, and potential challenges, researchers and practitioners can harness its power to build smarter, more responsive AI systems capable of addressing complex real-world problems.
Incorporating techniques such as temperature adjustment and entropy regularization can further optimize the Softmax Selection Policy, enhancing the overall performance of Deep Reinforcement Learning models. By addressing emerging trends, challenges, and limitations, researchers can pave the way for a new generation of AI applications that can learn, adapt, and excel in various scenarios.
In conclusion, the Softmax Selection Policy in Deep Reinforcement Learning is a powerful and versatile tool for optimizing decision-making processes in AI. Its potential for long-term ranking and impact on the future of Artificial Intelligence is undeniable. By embracing and mastering this knowledge, researchers and practitioners can unlock new possibilities and contribute to the ongoing advancement of AI technology.


