DQN: A Groundbreaking Approach to Reinforcement Learning
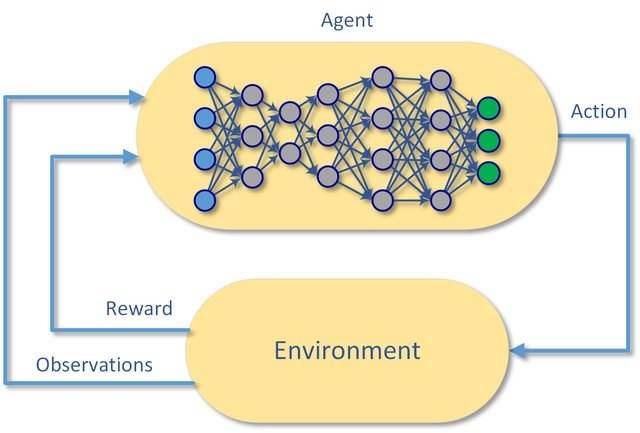
Deep Q-Network (DQN) revolutionized the realm of reinforcement learning (RL) by combining classic RL ideas with deep neural networks (DNNs). At its core lies the concept of Q-learning, which uses Q-values to estimate the expected cumulative reward of taking specific actions given certain states. By introducing DNNs, DQNs enable agents to process high-dimensional inputs, such as raw pixel values or financial time series data, thereby paving the way for solving intricate problems like cryptocurrency trading.

Click Image to Find Quantum Products
The foundation of DQN consists of two primary elements: the agent and the environment. The agent interacts with the environment by observing state information, executing actions, and receiving rewards. Over time, the agent refines its decision-making capabilities by minimizing the loss function associated with Q-value predictions, leading to improved overall performance.
In the context of cryptocurrency trading, DQNs can be employed to devise effective trading strategies by analyzing historical price movements, order book data, and other relevant market indicators. For instance, a DQN-powered bot could learn to recognize patterns signaling bullish or bearish trends, enabling it to buy low and sell high automatically. However, despite their prowess, vanilla DQNs suffer from limitations related to sample complexity and instability during training, necessitating enhancements to tackle these shortcomings adequately.
”
DDPG: Merging Actor-Critic Methods with Deep Neural Networks
Deep Deterministic Policy Gradient (DDPG) is an advanced deep reinforcement learning algorithm that combines the elegance of actor-critic methods with the robustness of deep neural networks. It was developed to address certain limitations in earlier algorithms, particularly those related to discrete action spaces and slow convergence rates.
At its core, DDPG consists of two primary components: the actor network and the critic network. The actor network takes the current state as input and generates a corresponding action directly, whereas the critic network evaluates the chosen action’s quality by computing its expected return—the sum of future rewards discounted over time. By iteratively updating both networks based on their respective loss functions, DDPG progressively refines its decision-making process.
One significant advantage of DDPG lies in its capacity to handle continuous action spaces efficiently. Traditional deep Q-learning (DQL) approaches struggle with high-dimensional actions since they rely on exhaustive enumeration and evaluation. However, DDPG sidesteps this issue by generating smooth, continuous actions via function approximation provided by deep neural networks. Consequently, DDPG has proven effective in various domains requiring precise control, such as robotics and navigation tasks.
Moreover, DDPG often exhibits faster convergence rates than conventional DQL methods thanks to its dual network architecture. By decoupling policy optimization from value estimation, DDPG reduces bias accumulation and promotes stable learning. Additionally, it employs experience replay buffers to facilitate sample efficiency, allowing the agent to learn from past experiences and stabilize training dynamics.
These attributes make DDPG an appealing choice for cryptocurrency trading scenarios where managing risks and optimizing returns are paramount. Its aptitude for navigating complex, dynamic environments aligns well with the intricate nature of financial markets. Furthermore, its capability to cope with continuous action spaces enables seamless integration with various trading strategies involving order sizes, entry points, exit conditions, and so forth.
PPO: Balancing Performance and Stability in Policy Optimization
Proximal Policy Optimization (PPO) is a cutting-edge deep reinforcement learning algorithm designed to strike a balance between performance and stability during policy optimization. Developed as an improvement upon vanilla policy gradients, PPO introduces modifications to the objective function that enhance learning efficiency while mitigating destructive divergences.
In essence, PPO seeks to minimize the difference between old and new policies during each update step. To achieve this goal, it utilizes a surrogate objective function that penalizes drastic changes to the policy distribution. By doing so, PPO ensures steady progression towards improved strategies while avoiding undesirable oscillatory behavior commonly observed in other policy gradient methods.
The suitability of PPO for cryptocurrency trading stems from its applicability in risk management scenarios. Financial markets inherently involve uncertainties and fluctuations, necessitating careful consideration of risks alongside potential profits. With its emphasis on incremental improvements and adaptability, PPO excels at navigating such challenging landscapes.
When deploying PPO for crypto trading bots, users can benefit from several key features. Firstly, PPO supports both discrete and continuous action spaces, accommodating diverse trading strategies encompassing buy/hold decisions or nuanced order placements. Secondly, PPO demonstrates rapid convergence rates owing to its self-regularized approach, enabling quick adaptation to evolving market conditions.
However, practitioners must remain cognizant of specific challenges associated with employing PPO in crypto trading. For instance, tuning hyperparameters requires meticulous attention to ensure alignment with the problem domain’s idiosyncrasies. Moreover, interpreting reward structures warrants caution, given the necessity of balancing short-term gains against long-term sustainability.

A2C & A3C: Parallelizing Advantage Actor-Critic Methods
Asynchronous Advantage Actor-Critic (A2C) and Asynchronous Methods for Actor-Critic Agents (A3C) are two prominent variants of the advantage actor-critic family in deep reinforcement learning (DRL). Both algorithms capitalize on parallelism to optimize training processes, rendering them particularly effective for managing complex environments characterized by numerous variables and concurrent events.
A2C: At its core, A2C synchronizes the experiences gathered by multiple agents interacting independently within the environment. By consolidating these experiences, A2C computes gradients used to update shared parameters across all agents. Consequently, this synchronized approach fosters consistent learning progression among individual entities operating within the same environment.
A3C: Expanding upon the foundation established by A2C, A3C incorporates separate learning threads for each agent. Instead of sharing global parameters after every iteration, A3C updates local model replicas per thread before periodically merging them into a single entity. Through this decentralized yet coordinated mechanism, A3C enhances overall robustness and scalability when confronted with intricate decision-making tasks.
These characteristics render A2C and A3C well-suited for cryptocurrency trading, wherein volatility often translates to rapidly shifting market dynamics. The capability to process myriad data streams simultaneously enables efficient analysis of fluctuating price patterns, order book depths, and liquidity indicators—all critical aspects influencing profitable trading strategies.
Nonetheless, prospective implementors should be aware of certain caveats. Primarily, achieving optimal results may require substantial computational resources due to the multi-threaded nature of these algorithms. Furthermore, striking an equilibrium between exploitation and exploration remains paramount; otherwise, overfitting could lead to suboptimal outcomes.

How to Implement these Algorithms for Crypto Trading Bots
Implementing deep reinforcement learning (DRL) algorithms into customized crypto trading bots requires careful consideration of various factors. Here’s a step-by-step guide covering library selection, development environment setup, API integration, and strategy backtesting.
- Choose Suitable Libraries: Select renowned open-source libraries such as TensorFlow or PyTorch to build your DRL models. Complementary tools like stable baselines3 simplify implementation by offering pre-implemented versions of popular DRL algorithms.
- Establish Development Environments: Set up virtual machines or containers utilizing platforms like Docker or Kubernetes to ensure consistent execution across diverse systems. Utilize version control systems (VCS) like GitHub to track code modifications and collaborate efficiently.
- Integrate Necessary APIs: Connect your DRL agent to reputable cryptocurrency exchanges via RESTful or WebSocket APIs. Commonly supported programming languages include Python, Node.js, and Java. Ensure secure access by employing authentication protocols such as OAuth2 or JWT tokens.
- Backtest Strategies: Simulate historical data feeds to assess your bot’s performance under different market conditions. Leverage specialized frameworks like Backtrader or Catalyst to streamline backtesting procedures. Monitor key performance indicators (KPIs) including profit factor, maximum drawdown, and Sharpe ratio to evaluate effectiveness.
By following these recommendations, you can successfully integrate top deep reinforcement learning algorithms for trading crypto into tailored automated trading systems. However, always remain vigilant regarding regulatory compliance and ethical conduct during live operations.

Selecting the Right Algorithm for Your Specific Use Case
When choosing from the best deep reinforcement learning algorithms for trading crypto, several factors come into play. Assessing these aspects will help you make informed decisions and optimize model performance according to your specific requirements.
- Computational Resources: More intricate DRL models necessitate substantial computing power and memory capacity. If limited hardware resources are available, opt for computationally efficient algorithms like DQN or PPO over resource-intensive ones such as DDPG or A3C.
- Trade Frequency: The ideal DRL algorithm also depends on the desired trading frequency. High-frequency traders might prefer rapid yet straightforward decision-making processes offered by methods like DQN or DDPG. Conversely, lower-frequency traders may find policy optimization algorithms like PPO better suited to handle strategic planning tasks.
- Risk Tolerance: Risk appetite significantly influences the choice of DRL algorithm. For instance, conservative investors prioritizing capital preservation could benefit from risk-averse models like PPO. Meanwhile, aggressive traders targeting higher returns despite increased volatility might lean towards DDPG or A3C.
Fine-tuning these models and continuously monitoring relevant performance metrics ensures ongoing adaptation to evolving market dynamics. By striking an optimal balance among computational efficiency, trading frequency, and risk tolerance, you can select the most fitting DRL algorithm for your particular use case.
Navigating Challenges and Limitations in Crypto Trading Using DRL
Applying deep reinforcement learning (DRL) algorithms to cryptocurrency trading presents certain obstacles that must be addressed. Understanding these challenges and devising effective solutions enables practitioners to harness the full potential of DRL in navigating dynamic financial markets.
- Non-Stationarity: Financial markets constantly change due to various exogenous factors influencing asset prices. To tackle this challenge, adaptive DRL agents employ mechanisms such as experience replay buffers and periodically updated target networks. Such techniques foster robust learning capabilities even amidst shifting market conditions.
- Latency Issues: Timeliness is critical in high-frequency trading scenarios involving cryptocurrencies. Minimizing communication delays between the DRL agent and environment requires low-latency connections alongside efficient data encoding and decoding protocols. Utilizing local exchange datacenters and GPU-accelerated frameworks helps mitigate latency concerns.
- Regulatory Constraints: Navigating regulatory landscapes poses another significant challenge for DRL-driven trading systems. Compliance measures often involve restricting access to sensitive information or imposing limitations on permitted actions. Adopting transparent reporting standards and incorporating ethical guardrails ensure adherence to legal obligations while maintaining system integrity.
By addressing these challenges proactively, organizations deploying DRL algorithms for trading crypto can effectively navigate complexities inherent in digital currency markets. Continuous innovation coupled with rigorous testing paves the way for enhanced performance and sustainable growth in this burgeoning domain.

Future Perspectives: Emerging Trends and Innovations in DRL for Crypto Trading
As the world of cryptocurrency continues evolving at breakneck speed, so too does the application of cutting-edge technologies like deep reinforcement learning (DRL) algorithms. The quest for optimizing trading strategies has led researchers down intriguing paths, exploring novel techniques and architectures that hold immense promise for enhancing profitability while managing risk.
- Transfer Learning: Applying knowledge acquired from one task directly to another related problem—known as transfer learning—is gaining traction among DRL practitioners. By pretraining models on historical price data or simulated environments before exposing them to live markets, developers can significantly reduce training times and improve overall performance.
- Multi-Agent Systems: Collaborative decision-making among multiple intelligent entities operating within a shared environment forms the basis of multi-agent systems. Leveraging swarm intelligence could enable more nuanced responses to rapidly changing market dynamics, ultimately leading to superior trading outcomes.
- Graph Neural Networks: Representing financial instruments as nodes within graph structures allows for better modeling of interdependencies among assets. Graph neural networks stand poised to capture subtle patterns hidden beneath layers of seemingly unrelated data points, thereby unlocking new avenues for exploiting arbitrage opportunities and capturing alpha.
Embracing these emergent trends demands both curiosity and courage but holds tremendous potential for those willing to push boundaries. Delving deeper into unfamiliar territories will undoubtedly yield valuable insights, fostering continued advancements in our understanding of how best to apply DRL algorithms for trading crypto.
