Deep Reinforcement Learning in Financial Markets
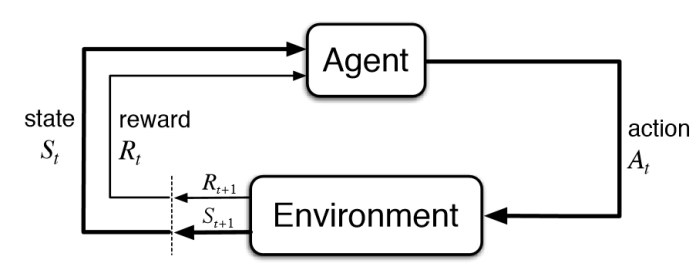
Deep Reinforcement Learning (DRL) has emerged as a promising artificial intelligence technique capable of transforming various sectors, including stock trading. The primary objective of DRL algorithms is to learn optimal decision-making policies through interactions within complex environments. By continuously refining their understanding of market dynamics, these advanced systems enable automated trading strategies designed to adapt to ever-changing market conditions. Consequently, integrating the best deep reinforcement learning algorithms for trading stocks offers significant potential for enhancing portfolio management and improving overall returns.

Click Image to Find Quantum Products

How to Choose the Best DRL Algorithm for Trading Stocks?
Selecting the ideal Deep Reinforcement Learning (DRL) algorithm for stock trading depends on several crucial factors. These elements ensure compatibility with specific use cases while addressing resource limitations and risk appetite. Here are essential aspects to consider:
- Data Availability: Assess whether sufficient historical price data exists for training your chosen model. Some sophisticated models require extensive datasets spanning multiple years, whereas simpler ones may suffice with shorter timeframes.
- Computational Requirements: Consider the hardware resources at hand since certain DRL algorithms demand substantial processing power and memory. For instance, Proximal Policy Optimization (PPO) typically requires fewer computations than other alternatives like Deep Q Networks (DQN).
- Risk Tolerance: Different algorithms exhibit varying levels of conservatism during decision-making processes. Traders prioritizing cautious approaches should opt for stable algorithms like TD3 over aggressive ones such as Dueling Double DQN (D3QN).
- Trade Frequency: High-frequency traders might prefer algorithms excelling in real-time decision-making, such as DDPG, handling continuous action spaces seamlessly.
- Ease of Implementation: Evaluate the complexity involved in setting up and fine-tuning each algorithm. Simpler models like REINFORCE often prove easier to implement initially but could lack the finesse offered by more intricate options like SAC.
Ultimately, balancing these factors will lead you towards the best deep reinforcement learning algorithms for trading stocks tailored to your needs and constraints.
Prominent DRL Algorithms Transforming Stock Trading
Various DRL algorithms have emerged as promising tools for stock trading, offering remarkable accuracy and adaptability. This section introduces three notable algorithms reshaping this landscape:
- Advantage Actor-Critic (A2C): A2C combines two primary components – actor and critic networks – enabling efficient policy gradient updates through advantage estimation. It reduces variance compared to traditional REINFORCE methods, thereby accelerating learning convergence. Moreover, A2C’s synchronous architecture facilitates parallelized training, making it an appealing choice for large-scale applications.
- Asynchronous Advantage Actor-Critic (A3C): A3C extends A2C by incorporating multiple independent agent instances, each interacting with separate environments concurrently. By sharing gradients among agents, A3C fosters improved generalization and stabilizes learning dynamics. Consequently, A3C demonstrates enhanced robustness against environmental fluctuations, rendering it suitable for unpredictable financial markets.
- Proximal Policy Optimization (PPO): PPO is another influential DRL method designed to address challenges associated with policy gradient instabilities. Instead of directly maximizing expected returns, PPO seeks to minimize Kullback-Leibler divergence between successive policies. This constraint ensures consistent update steps, preventing drastic deviations from optimal trajectories. Furthermore, PPO supports both discrete and continuous action spaces, providing flexibility for diverse trading scenarios.
These prominent DRL algorithms contribute significantly to enhancing trading strategies’ effectiveness, paving the way for further advancements in AI-assisted finance.

Profit-Driven Actor-Critic Methods (A2C & A3C)</h
Deep Deterministic Policy Gradient (DDPG)
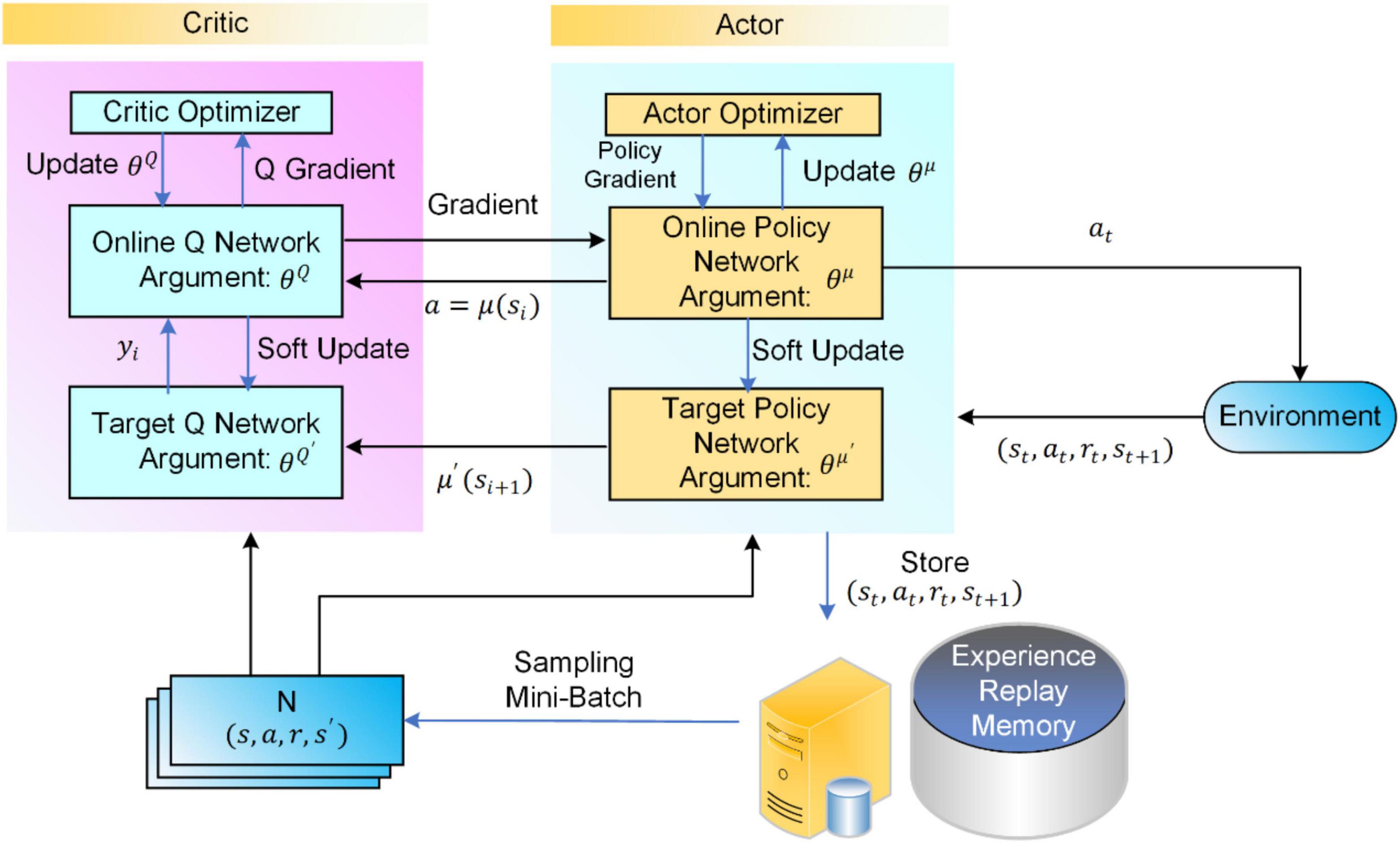
Among the best deep reinforcement learning algorithms for trading stocks is the Deep Deterministic Policy Gradient (DDPG) algorithm. This sophisticated method combines two primary components: an actor network and a critic network. The actor network generates actions given the current state, while the critic network evaluates those actions by estimating future rewards.
The DDPG algorithm operates within the framework of deterministic policies, making it highly suited for environments where discrete actions are not applicable. For instance, this feature proves advantageous in stock trading scenarios involving large order sizes since placing orders at specific prices falls under continuous action space.
Intraday high-frequency trading strategies significantly benefit from utilizing the DDPG algorithm due to its capability to manage continuous action spaces effectively. By continuously adjusting positions throughout the day, traders can capitalize on even minor price fluctuations, ultimately enhancing overall returns.
Twin Delayed DDPG (TD3)
Another prominent entry among the top deep reinforcement learning algorithms for trading stocks is Twin Delayed DDPG (TD3). TD3 builds upon the foundation laid by the DDPG algorithm but introduces several enhancements aimed at addressing limitations related to function approximation errors and overestimation issues inherent in DDPG.
One notable improvement found in TD3 involves the use of twin critics instead of a single one present in DDPG. These dual critics help mitigate overestimation concerns by exchanging information during training, thereby providing improved estimates of Q-values associated with different states and actions. Additionally, TD3 incorporates delayed policy updates, further bolstering stability and reducing estimation errors.
When comparing TD3 against other DRL algorithms like DDPG, it becomes evident that TD3 exhibits superior performance regarding stability and exploration capabilities. Consequently, adopting TD3 may lead to better outcomes in diverse market situations, ensuring consistent profits despite varying volatility levels.
Soft Actor-Critic (SAC)
Among the best deep reinforcement learning algorithms for trading stocks, Soft Actor-Critic (SAC) stands out due to its distinctive methodology centered around maximizing entropy. This unique characteristic allows SAC to achieve enhanced robustness across an array of market scenarios, making it an appealing choice for traders seeking consistency amid fluctuating conditions.
In essence, SAC aims not only to learn optimal policies guiding trading decisions but also strives to attain maximum entropy within those policies. By doing so, this algorithm fosters increased exploration while simultaneously maintaining exploitation efforts necessary for generating profits. The result is a well-balanced strategy capable of excelling even under challenging circumstances.
Moreover, SAC demonstrates remarkable sample efficiency – requiring fewer interactions with the environment than many alternative approaches. For traders working with limited datasets or facing strict computational constraints, employing SAC could prove advantageous given its proficiency in extracting valuable insights from scarce resources.

Comparing Algorithms and Selecting the Ideal Strategy
Having explored several prominent deep reinforcement learning (DRL) algorithms employed in stock trading, it becomes crucial to understand how they differ and determine which one aligns best with your specific needs as a trader. Various factors come into play when comparing these sophisticated techniques, including data availability, computational requirements, and risk tolerance.
For instance, if you possess ample historical price data and substantial computing power at your disposal, harnessing the prowess of advanced algorithms like Proximal Policy Optimization (PPO) or Soft Actor-Critic (SAC) may yield impressive results. These algorithms are renowned for handling complex environments efficiently and delivering robust performance despite noisy inputs or volatile market fluctuations.
Conversely, if your dataset is relatively small, or you face limitations in computational resources, simpler yet effective models such as Deep Q-Network (DQN) or Double Deep Q-Network (DDQN) might serve you better. Despite having lower computational demands, these algorithms still contribute significantly to refining AI-driven trading strategies by capitalizing on essential features like experience replay and target networks.
Ultimately, the ideal DRL algorithm depends on individual trader preferences, investment objectives, and resource allocation. Assessing each option’s merits against your unique criteria will ensure optimum alignment between chosen model and desired outcomes. To recap:
- Data Availability: Consider whether your dataset is extensive enough to support computationally intensive algorithms.
- Computational Requirements: Evaluate your hardware setup and decide accordingly; less demanding algorithms may suffice for modest configurations.
- Risk Tolerance: Opt for conservative choices when dealing with sensitive investments, whereas aggressive tactics can be adopted for higher risk appetite.
By carefully weighing these aspects, you stand to benefit from deploying the most appropriate DRL algorithm tailored to your distinct trading style and aspirations. Thus, empowered, embark upon your journey towards mastering AI-enhanced stock trading through informed decision-making and strategic planning.
:max_bytes(150000):strip_icc()/dotdash_Final_Algorithmic_Trading_Apr_2020-01-59aa25326afd47edb2e847c0e18f8ce2.jpg)