What is Reinforcement Learning? An Overview
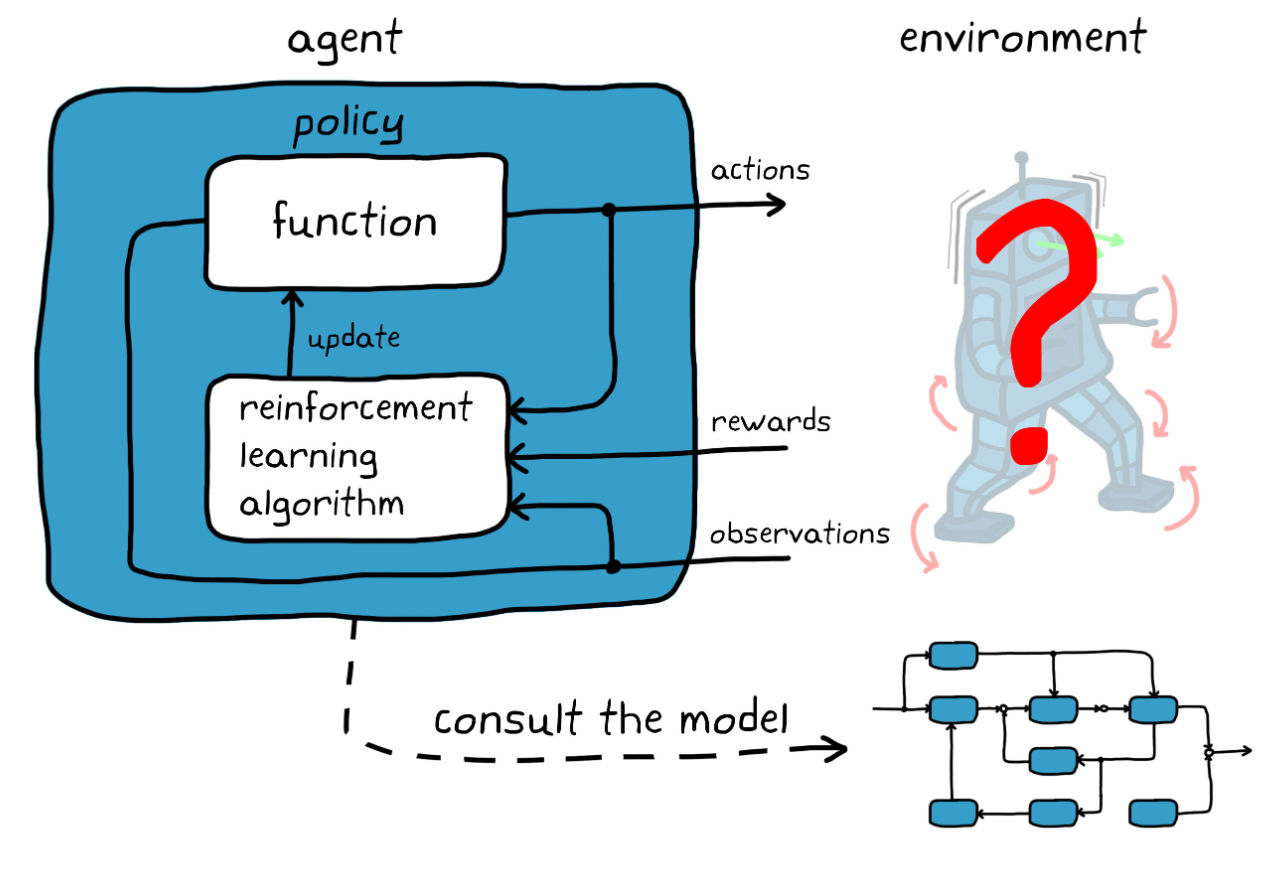
Reinforcement Learning (RL) is a specialized subset of machine learning focused on enabling artificial intelligence agents to determine the ideal sequence of actions based on interaction with their environment. By employing trial and error, RL concentrates on locating the optimal policy—a strategy guiding decision-making processes —to garner maximal cumulative reward over time. This sophisticated learning mechanism has emerged as a vital tool for addressing complex sequential decision-making tasks, thereby revolutionizing numerous sectors like robotics, gaming, finance, and self-driving cars.

Click Image to Find Quantum Products
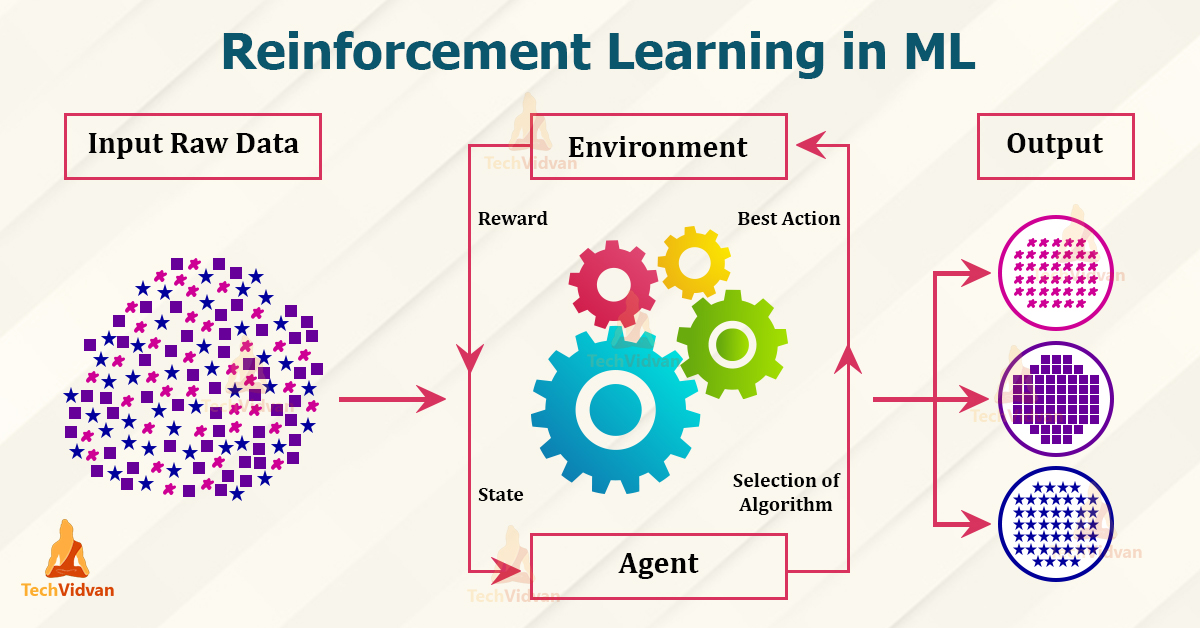
Key Components of Reinforcement Learning
In order to comprehend Reinforcement Learning (RL), one must familiarize themselves with five fundamental elements:
- Environments: Represent the world where the AI agent operates, consisting of all possible states and actions. For instance, in a game of chess, the environment includes the board layout and pieces.
- Agents: Denote the intelligent entities making decisions within the environment. They perceive their surroundings, select appropriate actions, and receive feedback via rewards or penalties.
- States: Characterize specific situations encountered by the agent during interactions with the environment. Examples of states could be distinct squares on a chessboard or varying positions of a robotic arm.
- Actions: Symbolize choices made by the agent at each state intending to influence future states and obtain higher rewards. These may range from moving a chess piece to adjusting motor torque in robotics.
- Rewards: Signify scalar numeric values reflecting the desirability of outcomes resulting from particular state-action pairs. Higher rewards encourage the pursuit of similar actions, while lower ones discourage repetition.
Mastery of these core components paves the way towards grasping advanced RL concepts and developing proficient AI decision-makers capable of excelling in diverse fields.

Reinforcement Learning Algorithms: A Broad Perspective
As we delve deeper into the realm of Reinforcement Learning (RL), it becomes crucial to explore various algorithm classes designed to address disparate problems effectively. Here are three prominent categories:
- Value Iteration: This methodology revolves around estimating the optimal value function, which signifies the highest expected discounted sum of rewards attainable from every state. By repeatedly refining these estimates, value iteration ultimately converges upon the ideal strategy known as the optimal policy.
- Policy Gradient Methods: Unlike value iteration, policy gradient approaches focus on enhancing policies directly instead of relying on intermediary value functions. Such techniques prove particularly advantageous when handling high-dimensional or continuous action spaces since they circumvent complexities associated with discretization.
- Actor-Critic Methods: As a blend of value iteration and policy gradients, actor-critic methods employ value function approximations alongside concurrent policy updates. This dual-faceted mechanism enables efficient learning processes, rendering them popular amongst contemporary RL practitioners seeking robust performance combined with computational economy.
By gaining awareness of these varied RL algorithms, you empower yourself to tackle diverse challenges inherent in numerous real-world scenarios, thereby unlocking immense possibilities for innovation and progression.
Value Iteration: The Basics
In our ongoing discussion about the quick manual to understand reinforcement learning, let’s dive into one of the fundamental RL algorithms called Value Iteration. This technique aims at determining the optimal policy by successively refining action values until achieving convergence.
To clarify, imagine being in a specific “state” within an environment (e.g., playing chess as white). You have multiple possible moves or “actions,” each leading to distinct outcomes represented by unique subsequent states accompanied by varying rewards. Action values represent the anticipated future rewards derived from taking those actions.
The core idea behind Value Iteration lies in recursively updating action values based on the maximum estimated return obtainable from next reachable states. It does so via the following formula:
Action-value(s, a) ← ∑s’ P(s, a, s’)[R(s, a, s’) + γ maxa’ Action-value(s’, a’)],
where:
- “P(s, a, s’)” denotes the probability transition dynamics, specifying the likelihood of moving from state “s” to state “s’” after executing action “a”;
- “R(s, a, s’)” represents the immediate reward acquired during the transition;
- “γ” stands for the discount factor

Policy Gradient Methods: Bridging the Gap
As we delve deeper into the quick manual to understand reinforcement learning, let us explore Policy Gradient Methods – another crucial category of RL algorithms. These approaches focus on optimizing policies directly instead of relying on value functions, which sets them apart from methods like Value Iteration.
Conventional wisdom suggests that estimating action values accurately leads to improved decision-making. However, challenges arise when handling high-dimensional or continuous action spaces since evaluating every conceivable outcome becomes impractical. To tackle these complexities, Policy Gradient Methods step in.
At their core, Policy Gradient Methods adjust parameters governing the stochastic policy (π) to increase the expected total reward gradually. Mathematically speaking, they update the policy along the direction of the gradient ascend for the objective function:
∇θJ(θ) = Eπθ [∇θ log ϕ(a|s, θ) Q^Δ(s, a)]
Here,
- θ signifies the set of parameters defining the current policy;
- Q^Δ(s, a) refers to the action-value function associated with the optimal policy;
- log ϕ(a|s, θ) calculates the logarithm of the probability of selecting action “a” given state
Actor-Critic Methods: Combining Strengths
In our quest to comprehend the quick manual to understand reinforcement learning, it’s time to dive into Actor-Critic Methods – a sophisticated blend of two distinct RL strategies. As the name implies, these methods integrate elements from both value function approximations and direct policy optimization, making them highly efficient and popular amongst contemporary RL techniques.
To better appreciate how Actor-Critic Methods operate, let’s briefly recollect key aspects of Value Iteration and Policy Gradient Methods. Value Iteration primarily concentrates on refining action values based on Bellman Optimality Equation principles, while Policy Gradient Methods specialize in updating policy parameters guided by estimated gradients in the objective function space. By merging ideas from these separate realms, Actor-Critic Methods aim to strike an equilibrium between exploitation and exploration during the learning process.
The term ‘Actor-Critic’ arises due to the division of labor within the framework. Specifically, one part assumes responsibility for acting (selecting appropriate actions) and another assesses performance (evaluating chosen actions). This allocation enables more accurate credit assignment and facilitates faster convergence rates compared to traditional policy gradient approaches.
Some prominent variations of Actor-Critic Methods encompass Advantage Actor Critic (A2C) and Proximal Policy Optimization (PPO). Both have garnered considerable attention owing to their robustness and applicability across diverse domains.
Applications of Reinforcement Learning
As we delve deeper into the realm of the quick manual to understand reinforcement learning, exploring its practical implications becomes crucial. Reinforcement Learning (RL) has demonstrated remarkable prowess in solving complex decision-making problems across numerous industries, showcasing impressive adaptability and transformative capabilities.
- Robotics: RL empowers robots to master challenging tasks like grasping objects, navigating mazes, and performing intricate maneuvers. Through trial and error, machines can develop dexterity and resilience, leading to enhanced productivity and safety in industrial settings.
- Gaming: AlphaGo, developed by Google DeepMind, harnessed RL to conquer the ancient game of Go, outsmarting world champions. Similarly, other video games benefit from AI-powered bots capable of strategizing and adapting dynamically, providing immersive experiences for players.
- Finance: Financial institutions utilize RL to optimize trading strategies, manage risk portfolios, and detect fraudulent activities. These intelligent systems enable organizations to minimize losses, improve profitability, and ensure regulatory compliance.
- Autonomous Vehicles: Self-driving cars heavily rely on RL algorithms to navigate roads, recognize traffic signs, and respond to unforeseen events. Integrating RL with computer vision technologies paves the way for safer transportation networks and smarter cities.
These illustrative examples underscore the vast potential of RL in revolutionizing multiple sectors. With ongoing advancements in computational power, data storage, and connectivity, the influence of RL will only continue to expand, offering unprecedented opportunities for innovation and growth.
Further Resources for Mastering Reinforcement Learning
To augment your comprehension of the quick manual to understand reinforcement learning, you may find these resources helpful in deepening your knowledge and refining your skills within this fascinating field. Dedicated study materials catering to diverse preferences are available, ensuring ample opportunity for every learner to thrive.
- Books: Delve into classic texts such as ““Reinforcement Learning: An Introduction ““by Richard Sutton and Andrew Barto or explore contemporary publications like ““Hands-On Reinforcement Learning with Python ““by Bonnie Eisenman. Both offer thorough introductions while addressing specific aspects of RL theory and practice.
- Online Courses: Platforms such as Coursera, edX, Udacity, and YouTube host a wealth of structured coursework covering RL fundamentals and advanced topics. For instance, University of Alberta’s “Introduction to Artificial Intelligence (AI)” on Coursera provides a strong foundation in RL principles.
- Tutorials: Engaging tutorials abound on websites like Medium, Towards Data Science, and GitHub. Tutorials often feature hands-on code implementations alongside theoretical explanations, making them ideal for visual learners seeking interactive lessons.
- Research Papers: Stay up-to-date with cutting-edge breakthroughs by perusing scholarly articles published in esteemed journals such as “Journal of Machine Learning Research “and conference proceedings like Neural Information Processing Systems (NIPS). Reading recent work helps keep your expertise current and relevant.
By incorporating these supplementary resources into your self-directed education journey, you stand to significantly enhance your proficiency in the domain of reinforcement learning. Remember, consistent effort coupled with curiosity fosters true mastery; thus, never cease questioning, practicing, and expanding your horizons.