The Art of Training Predictive Models
Predictive modeling is a powerful tool in modern data analysis, enabling organizations and individuals to forecast future trends, identify patterns, and make informed decisions based on data-driven insights. At its core, predictive modeling involves training models to learn patterns from data and then using those models to make predictions about new, unseen data. Effective training of predictive models is crucial for achieving accurate and reliable results, and analyzing machine learning results plays a vital role in refining and improving models over time.

Click Image to Find Quantum Products
Predictive modeling is a multidisciplinary field that combines elements of statistics, computer science, and domain-specific knowledge. It has numerous applications across various industries, including finance, healthcare, marketing, and manufacturing. In finance, predictive models can be used to forecast stock prices, detect fraud, and manage risk. In healthcare, they can help predict patient outcomes, optimize treatment plans, and improve disease diagnosis. In marketing, predictive models can assist in customer segmentation, churn prediction, and personalized recommendations. In manufacturing, they can be employed for predictive maintenance, quality control, and demand forecasting.
To train predictive models effectively, it is essential to follow a structured and systematic approach. This approach should encompass various stages, including selecting the right machine learning algorithm, preparing and preprocessing data, feature engineering and selection, model training and hyperparameter tuning, model evaluation and validation, interpreting and analyzing results, and continuous model improvement and monitoring. By adhering to best practices in each of these stages, data scientists and analysts can significantly enhance the performance, reliability, and applicability of their predictive models.

Selecting the Right Machine Learning Algorithm
In the realm of predictive modeling, choosing the appropriate machine learning algorithm is crucial for achieving accurate and reliable results. With a vast array of algorithms available, each with its unique strengths, weaknesses, and applications, selecting the most suitable algorithm can be a challenging task. This section will discuss various machine learning algorithms and their applications, as well as the process of selecting the most appropriate algorithm based on the problem statement, data availability, and desired outcomes.
Machine learning algorithms can be broadly categorized into three main types: supervised learning, unsupervised learning, and reinforcement learning. Supervised learning algorithms involve training models using labeled data, where the input data and corresponding output labels are provided. Common supervised learning algorithms include linear regression, logistic regression, decision trees, random forests, support vector machines (SVM), and neural networks. These algorithms are widely used for classification and regression tasks, such as predicting customer churn, sentiment analysis, and demand forecasting.
Unsupervised learning algorithms, on the other hand, involve training models using unlabeled data, where only the input data is provided, and the model must identify patterns and relationships within the data. Common unsupervised learning algorithms include clustering algorithms, such as k-means clustering and hierarchical clustering, as well as dimensionality reduction techniques, such as principal component analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE). These algorithms are often used for anomaly detection, customer segmentation, and data visualization.
Reinforcement learning algorithms involve training models to make decisions in a dynamic environment, where the model receives feedback in the form of rewards or penalties for its actions. These algorithms are commonly used in robotics, gaming, and autonomous systems, such as self-driving cars. Examples of reinforcement learning algorithms include Q-learning, deep Q-networks (DQN), and policy gradients.
When selecting a machine learning algorithm, it is essential to consider the problem statement, data availability, and desired outcomes. Factors such as the size, complexity, and structure of the data, as well as the specific problem being addressed, can significantly influence the choice of algorithm. For instance, linear regression may be a suitable choice for a simple, linear relationship between input and output variables, while a decision tree or random forest may be more appropriate for complex, non-linear relationships. Similarly, if the data is highly dimensional or noisy, dimensionality reduction techniques or neural networks may be more effective in identifying patterns and relationships within the data.
Ultimately, selecting the right machine learning algorithm is a matter of balancing the trade-offs between model complexity, interpretability, and performance. By carefully considering the problem statement, data availability, and desired outcomes, data scientists and analysts can make informed decisions about the most suitable algorithm for their predictive modeling tasks.
Data Preparation and Preprocessing: A Crucial Step in Training Predictive Models
Predictive modeling is a powerful tool in modern data analysis, enabling organizations to make informed decisions based on data-driven insights. However, the effectiveness of predictive models heavily depends on the quality of the data used to train them. High-quality data can lead to accurate and reliable models, while poor-quality data can result in models that are biased, inaccurate, or unreliable. Therefore, data preparation and preprocessing are crucial steps in training predictive models and analyzing machine learning results.
Data preparation and preprocessing involve a series of techniques aimed at cleaning, transforming, and normalizing the data to improve model performance. These techniques include handling missing values, removing outliers, encoding categorical variables, scaling numerical variables, and transforming the data to meet the assumptions of the machine learning algorithms. By applying these techniques, data scientists and analysts can ensure that the data used to train predictive models is of high quality, accurate, and reliable.
Handling missing values is an essential step in data preparation and preprocessing. Missing values can occur due to various reasons, such as human error, data corruption, or incomplete data collection. There are several techniques for handling missing values, including imputation, deletion, and using algorithms that can handle missing values. Imputation involves replacing missing values with estimated values based on the available data. Deletion involves removing rows or columns with missing values. Using algorithms that can handle missing values involves selecting machine learning algorithms that can handle missing values without requiring imputation or deletion.
Removing outliers is another critical step in data preparation and preprocessing. Outliers are data points that deviate significantly from the rest of the data, and they can negatively impact model performance. There are several techniques for removing outliers, including using statistical methods, such as the Z-score or the IQR method, or using machine learning algorithms that can handle outliers, such as robust regression or decision trees.
Encoding categorical variables is a crucial step in data preparation and preprocessing, especially when using machine learning algorithms that cannot handle categorical variables directly. Encoding categorical variables involves converting them into numerical variables, such as using one-hot encoding or label encoding. Scaling numerical variables is another essential step in data preparation and preprocessing, especially when using machine learning algorithms that are sensitive to the scale of the data. Scaling involves transforming the data to have a mean of zero and a standard deviation of one, which can improve model performance and convergence.
Transforming the data to meet the assumptions of the machine learning algorithms is the final step in data preparation and preprocessing. Machine learning algorithms make certain assumptions about the data, such as linearity, normality, or homoscedasticity. Transforming the data to meet these assumptions can improve model performance and convergence. Techniques for transforming the data include using logarithmic or polynomial transformations, using Box-Cox or Yeo-Johnson transformations, or using non-parametric methods, such as decision trees or random forests.
In conclusion, data preparation and preprocessing are crucial steps in training predictive models and analyzing machine learning results. By applying techniques such as handling missing values, removing outliers, encoding categorical variables, scaling numerical variables, and transforming the data, data scientists and analysts can ensure that the data used to train predictive models is of high quality, accurate, and reliable. These steps can significantly impact model performance and convergence, leading to accurate and reliable models that can provide valuable insights and drive informed decision-making.
Feature Engineering and Selection: Enhancing Predictive Models
Predictive modeling is a powerful tool in modern data analysis, enabling organizations to make informed decisions based on data-driven insights. However, the effectiveness of predictive models heavily depends on the quality of the data used to train them. Feature engineering and selection are crucial steps in enhancing predictive models by creating new features, reducing dimensionality, and selecting the most relevant features for model training. This article discusses the importance of feature engineering and selection in training predictive models and analyzing machine learning results.
Feature engineering is the process of creating new features from existing data to improve model performance. This process involves transforming raw data into a more useful and informative format that can help machine learning algorithms make accurate predictions. Feature engineering can include techniques such as aggregation, interaction, and transformation. Aggregation involves combining multiple features into a single feature, such as calculating the average of several numerical variables. Interaction involves creating new features by combining two or more features, such as creating a product of two numerical variables. Transformation involves applying mathematical functions to features, such as logarithmic or polynomial transformations.
Dimensionality reduction is another crucial aspect of feature engineering and selection. High-dimensional data can lead to overfitting, which occurs when a model is too complex and fits the training data too closely, resulting in poor generalization to new data. Dimensionality reduction techniques can help mitigate overfitting by reducing the number of features in the dataset while preserving the essential information. Techniques for dimensionality reduction include principal component analysis (PCA), linear discriminant analysis (LDA), and t-distributed stochastic neighbor embedding (t-SNE).
Feature selection is the process of selecting the most relevant features for model training. This process can help improve model performance, reduce overfitting, and decrease training time. Feature selection techniques can be categorized into filter, wrapper, and embedded methods. Filter methods involve selecting features based on statistical measures, such as correlation or mutual information. Wrapper methods involve selecting features based on the performance of the machine learning algorithm. Embedded methods involve selecting features as part of the model training process, such as using Lasso or Ridge regression.
When it comes to selecting the most suitable algorithm for feature engineering and selection, there are several options available. Some popular algorithms for feature engineering and selection include recursive feature elimination (RFE), recursive feature addition (RFA), and genetic algorithms. RFE involves recursively removing features and evaluating the model performance to select the optimal set of features. RFA involves recursively adding features and evaluating the model performance to select the optimal set of features. Genetic algorithms involve using evolutionary algorithms to select the optimal set of features based on the fitness function.
In conclusion, feature engineering and selection are crucial steps in enhancing predictive models by creating new features, reducing dimensionality, and selecting the most relevant features for model training. By applying techniques such as aggregation, interaction, transformation, dimensionality reduction, and feature selection, data scientists and analysts can improve model performance, reduce overfitting, and decrease training time. These steps can significantly impact model performance and convergence, leading to accurate and reliable models that can provide valuable insights and drive informed decision-making. When selecting the most suitable algorithm for feature engineering and selection, it is essential to consider the problem statement, data availability, and desired outcomes to ensure the best possible results.

Model Training and Hyperparameter Tuning: How to Train Predictive Models and Analyze Machine Learning Results
Predictive modeling is a critical component of modern data analysis, enabling organizations to make informed decisions based on data-driven insights. Training predictive models effectively and analyzing machine learning results are crucial steps in refining models and ensuring long-term success. This article focuses on model training and hyperparameter tuning, which involve optimizing model performance using various techniques.
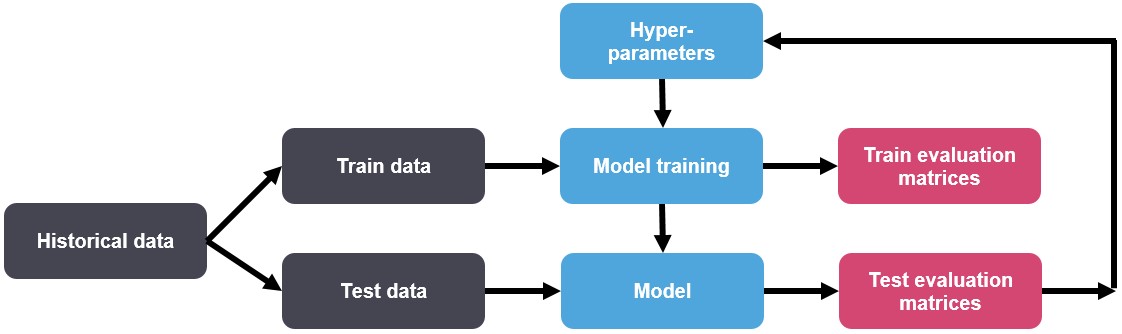
Model training is the process of fitting a machine learning algorithm to a dataset to make predictions. The goal of model training is to find the best set of model parameters that minimize the difference between the predicted and actual values. Model training involves splitting the dataset into training and testing sets, where the training set is used to train the model, and the testing set is used to evaluate the model’s performance. Cross-validation is another technique used to evaluate model performance by splitting the dataset into multiple folds and training and testing the model on each fold.
Hyperparameter tuning is the process of selecting the optimal set of hyperparameters for a machine learning algorithm. Hyperparameters are parameters that are not learned from the data but are set before training the model. Examples of hyperparameters include the learning rate, regularization strength, and number of hidden layers in a neural network. Hyperparameter tuning involves selecting the optimal set of hyperparameters that result in the best model performance. Techniques for hyperparameter tuning include grid search, random search, and Bayesian optimization.
Grid search involves defining a range of values for each hyperparameter and training the model with all possible combinations of hyperparameters. The combination that results in the best model performance is selected as the optimal set of hyperparameters. Random search involves randomly selecting hyperparameters from a defined range and training the model with each combination. Bayesian optimization involves using a probabilistic model to select the most promising hyperparameters to train the model. This approach is more efficient than grid search and random search, as it focuses on exploring the most promising hyperparameters.
When it comes to selecting the most suitable algorithm for model training and hyperparameter tuning, there are several options available. Some popular algorithms for model training and hyperparameter tuning include linear regression, logistic regression, decision trees, random forests, and neural networks. The choice of algorithm depends on the problem statement, data availability, and desired outcomes. For example, linear regression is suitable for predicting continuous outcomes, while logistic regression is suitable for predicting binary outcomes. Decision trees and random forests are suitable for handling non-linear relationships and high-dimensional data. Neural networks are suitable for handling complex relationships and large datasets.
In conclusion, model training and hyperparameter tuning are crucial steps in training predictive models and analyzing machine learning results. By applying techniques such as splitting data into training and testing sets, cross-validation, and hyperparameter tuning, data scientists and analysts can optimize model performance, reduce overfitting, and improve generalization to new data. These steps can significantly impact model performance and convergence, leading to accurate and reliable models that can provide valuable insights and drive informed decision-making. When selecting the most suitable algorithm for model training and hyperparameter tuning, it is essential to consider the problem statement, data availability, and desired outcomes to ensure the best possible results.
Model Evaluation and Validation: How to Assess Predictive Model Performance
Model evaluation and validation are critical components of predictive modeling, enabling data scientists and analysts to assess the performance of their models and refine them as needed. By employing various metrics for assessing model performance, such as accuracy, precision, recall, F1 score, and area under the ROC curve, data professionals can ensure that their models are reliable, accurate, and effective in making predictions. This article focuses on model evaluation and validation, providing a comprehensive overview of how to assess predictive model performance.
Accuracy is a common metric used to evaluate the performance of predictive models. It measures the proportion of correct predictions made by the model out of the total number of predictions. However, accuracy alone is not always a reliable metric, especially when dealing with imbalanced datasets where one class may have significantly more instances than another. In such cases, precision and recall become more important metrics.
Precision measures the proportion of true positive predictions out of all positive predictions made by the model. It is a useful metric when dealing with imbalanced datasets, as it provides a better understanding of the model’s ability to correctly identify positive instances. Recall, on the other hand, measures the proportion of true positive predictions out of all actual positive instances in the dataset. It is a useful metric when the cost of false negatives is high, as it provides a better understanding of the model’s ability to identify all positive instances.
The F1 score is a metric that combines precision and recall into a single score, providing a balanced assessment of a model’s performance. It is a useful metric when dealing with imbalanced datasets, as it takes into account both the model’s ability to correctly identify positive instances and its ability to identify all positive instances. The area under the ROC curve (AUC-ROC) is a metric that measures the model’s ability to distinguish between positive and negative instances. It is a useful metric when dealing with binary classification problems, as it provides a better understanding of the model’s ability to rank instances based on their predicted probabilities.
Cross-validation is a technique used to validate the performance of predictive models. It involves splitting the dataset into multiple folds, training the model on one fold, and testing it on another fold. This process is repeated for each fold, providing a more robust assessment of the model’s performance than simply splitting the dataset into training and testing sets. Cross-validation can help prevent overfitting, improve model generalization, and provide a more accurate assessment of model performance.
When it comes to selecting the most suitable metric for model evaluation and validation, it is essential to consider the problem statement, data availability, and desired outcomes. For example, accuracy may be a suitable metric for a balanced dataset with equal class distributions, while precision and recall may be more appropriate for an imbalanced dataset. The F1 score and AUC-ROC are useful metrics for assessing the overall performance of a model, especially in binary classification problems.
In conclusion, model evaluation and validation are critical components of predictive modeling, enabling data scientists and analysts to assess the performance of their models and refine them as needed. By employing various metrics for assessing model performance, such as accuracy, precision, recall, F1 score, and area under the ROC curve, data professionals can ensure that their models are reliable, accurate, and effective in making predictions. Cross-validation is a technique used to validate the performance of predictive models, providing a more robust assessment of the model’s performance than simply splitting the dataset into training and testing sets. When selecting the most suitable metric for model evaluation and validation, it is essential to consider the problem statement, data availability, and desired outcomes to ensure the best possible results.
Interpreting and Analyzing Machine Learning Results to Refine Predictive Models
Predictive modeling and machine learning have become essential tools in modern data analysis, enabling data professionals to make accurate predictions and draw valuable insights from complex datasets. However, the effectiveness of predictive models is heavily dependent on the ability to interpret and analyze machine learning results. By employing various techniques for visualizing results, identifying patterns, and drawing insights from the data, data scientists and analysts can refine their predictive models and improve their overall performance.
Visualizing machine learning results is a critical step in the predictive modeling process. By creating visual representations of the data, data professionals can gain a better understanding of the relationships between variables, identify patterns and trends, and detect anomalies or outliers. Common visualization techniques used in machine learning include scatter plots, line charts, bar charts, and heatmaps. These visualizations can help data professionals identify areas for improvement in their predictive models and refine them accordingly.
Identifying patterns and trends in the data is another essential aspect of interpreting and analyzing machine learning results. By examining the relationships between variables and identifying trends in the data, data professionals can gain insights into the underlying patterns that drive the data. These insights can then be used to refine predictive models and improve their accuracy. Techniques for identifying patterns and trends in the data include correlation analysis, regression analysis, and time series analysis.
Drawing insights from the data is the ultimate goal of predictive modeling and machine learning. By analyzing the results of predictive models, data professionals can draw valuable insights into the underlying patterns and relationships in the data. These insights can then be used to inform business decisions, optimize processes, and improve overall performance. Techniques for drawing insights from the data include statistical analysis, machine learning algorithms, and data mining.
When it comes to interpreting and analyzing machine learning results, it is essential to consider the problem statement, data availability, and desired outcomes. For example, if the goal is to predict customer churn, visualizing the data using a scatter plot may help identify patterns and trends in the data that indicate customer dissatisfaction. Identifying these patterns and trends can then be used to refine the predictive model and improve its accuracy. Similarly, if the goal is to optimize a marketing campaign, regression analysis may be used to identify the variables that have the greatest impact on customer engagement, enabling data professionals to refine their marketing strategy and improve its effectiveness.
In conclusion, interpreting and analyzing machine learning results are critical components of predictive modeling, enabling data scientists and analysts to refine their predictive models and improve their overall performance. By employing various techniques for visualizing results, identifying patterns and trends, and drawing insights from the data, data professionals can ensure that their predictive models are reliable, accurate, and effective in making predictions. When interpreting and analyzing machine learning results, it is essential to consider the problem statement, data availability, and desired outcomes to ensure the best possible results. By following these best practices, data professionals can unlock the full potential of predictive modeling and machine learning, driving business success and improving overall performance.

Continuous Model Improvement and Monitoring: Ensuring Long-Term Success in Predictive Modeling
Predictive modeling and machine learning have become essential tools in modern data analysis, enabling data professionals to make accurate predictions and draw valuable insights from complex datasets. However, the effectiveness of predictive models is not a one-time achievement but a continuous process that requires ongoing improvement and monitoring. By employing various techniques for re-training models, updating data, and monitoring model performance over time, data scientists and analysts can ensure the long-term success of their predictive models.
Re-training predictive models is a critical aspect of continuous model improvement. Over time, as new data becomes available, predictive models may become less accurate or outdated. By re-training models using the latest data, data professionals can ensure that their predictive models remain up-to-date and accurate. Techniques for re-training predictive models include incremental learning, where the model is updated with new data periodically, and batch learning, where the model is re-trained using the entire dataset at regular intervals.
Updating data is another essential aspect of continuous model improvement. As new data becomes available, data professionals should update their predictive models with the latest information. This can include new customer data, market trends, or other relevant information that can impact the accuracy of the predictive model. By updating data regularly, data professionals can ensure that their predictive models remain relevant and accurate over time.
Monitoring model performance is critical to ensuring the long-term success of predictive models. By tracking model performance over time, data professionals can identify areas for improvement and refine their predictive models accordingly. Techniques for monitoring model performance include tracking key performance indicators (KPIs), such as accuracy, precision, recall, and F1 score, and conducting regular model evaluations using techniques such as cross-validation and A/B testing.
When it comes to continuous model improvement and monitoring, it is essential to consider the problem statement, data availability, and desired outcomes. For example, if the goal is to predict customer churn, monitoring model performance using KPIs such as precision and recall may be more relevant than accuracy. Similarly, if the goal is to optimize a marketing campaign, tracking KPIs such as conversion rate and return on investment (ROI) may be more relevant than other metrics. By considering the problem statement, data availability, and desired outcomes, data professionals can ensure that their continuous model improvement and monitoring efforts are aligned with their overall business objectives.
In conclusion, continuous model improvement and monitoring are critical components of predictive modeling, enabling data scientists and analysts to ensure the long-term success of their predictive models. By employing various techniques for re-training models, updating data, and monitoring model performance over time, data professionals can ensure that their predictive models remain up-to-date, relevant, and accurate. When it comes to continuous model improvement and monitoring, it is essential to consider the problem statement, data availability, and desired outcomes to ensure the best possible results. By following these best practices, data professionals can unlock the full potential of predictive modeling and machine learning, driving business success and improving overall performance.