Demystifying Ensemble Deep Reinforcement Learning Strategies in Trading
Ensemble Deep Reinforcement Learning (DRL) has emerged as a promising approach to developing robust and accurate trading strategies. By combining multiple DRL models, ensemble methods can enhance the overall performance of trading systems, making them more resilient to market fluctuations and less prone to overfitting. This article introduces the concept of ensemble DRL trading strategies and sheds light on their relevance in the trading industry.

Click Image to Find Quantum Products
Deep reinforcement learning, a subset of machine learning, enables agents to learn optimal decision-making policies through interactions with an environment. In the context of trading, these agents learn to execute trades based on market conditions, with the goal of maximizing profits. However, traditional DRL models can be sensitive to noise and prone to overfitting, especially when applied to financial markets with their inherent complexities and uncertainties.
Enter ensemble DRL trading strategies. By combining the predictions of multiple DRL models, these strategies can achieve improved accuracy, reduced overfitting, and increased robustness. The underlying idea is to leverage the strengths of individual models while mitigating their weaknesses. This approach has been shown to enhance the performance of trading systems, making them more adaptive to changing market conditions and less susceptible to the pitfalls of relying on a single model.
The relevance of ensemble DRL trading strategies in the trading industry is manifold. First, they offer a more holistic approach to trading, incorporating diverse perspectives and reducing the reliance on any single model. Second, they can help mitigate the risks associated with traditional DRL models, such as overfitting and sensitivity to noise. Third, ensemble DRL trading strategies can adapt to evolving market conditions more effectively, ensuring long-term profitability and sustainability.
Key Components of an Ensemble Deep Reinforcement Learning Trading Strategy
An ensemble deep reinforcement learning (DRL) trading strategy comprises several essential components that work together to optimize trading decisions. These components include state representation, action space, reward function, and policy optimization. Understanding these components is crucial for developing effective ensemble DRL trading strategies.
State Representation
State representation refers to the features or variables used to describe the current market conditions. These features can include technical indicators, price movements, volume, and other relevant market data. A well-designed state representation should capture the essential aspects of the market, enabling the DRL agent to make informed decisions based on the current and historical data.
Action Space
The action space defines the set of possible actions that the DRL agent can take in response to the current state. In the context of trading, actions may include buying, selling, or holding a financial instrument. The action space should be carefully designed to balance exploration and exploitation, allowing the agent to learn optimal trading strategies while avoiding excessive risk.
Reward Function
The reward function quantifies the desirability of a particular action, guiding the DRL agent towards profitable trading decisions. In an ensemble DRL trading strategy, the reward function should be designed to encourage long-term profitability, taking into account factors such as transaction costs, slippage, and risk management. A well-designed reward function should strike a balance between maximizing profits and minimizing risk, ensuring the sustainability of the trading strategy.
Policy Optimization
Policy optimization is the process of learning an optimal policy, or a mapping from states to actions, that maximizes the expected cumulative reward. Various DRL algorithms, such as Deep Q-Networks (DQN), Proximal Policy Optimization (PPO), and Asynchronous Advantage Actor-Critic (A3C), employ different techniques for policy optimization. The choice of algorithm depends on the specific requirements of the trading problem, such as the complexity of the state space, the dimensionality of the action space, and the desired convergence properties.
By carefully designing these key components, ensemble DRL trading strategies can achieve improved accuracy, reduced overfitting, and increased robustness, ultimately leading to more profitable and sustainable trading systems.
Selecting and Training Individual Deep Reinforcement Learning Models
A crucial step in building an ensemble deep reinforcement learning (DRL) trading strategy involves selecting and training individual DRL models. Various DRL algorithms, such as Deep Q-Networks (DQN), Proximal Policy Optimization (PPO), and Asynchronous Advantage Actor-Critic (A3C), each have their unique strengths and weaknesses. Understanding these characteristics can help you choose the most suitable algorithm for your specific trading problem.
Deep Q-Networks (DQN)
DQN is a value-based DRL algorithm that approximates the action-value function using a deep neural network. DQN is well-suited for trading problems with discrete action spaces, such as buying, selling, or holding a financial instrument. Its primary advantage lies in its simplicity and stability, making it an excellent starting point for developing DRL trading strategies. However, DQN may struggle with high-dimensional action spaces and may require significant computational resources for training.
Proximal Policy Optimization (PPO)
PPO is a policy-based DRL algorithm that directly optimizes the policy function, maximizing the expected cumulative reward. PPO is particularly effective for trading problems with continuous action spaces, such as determining the optimal position size for a trade. PPO’s main strength is its ability to balance exploration and exploitation, leading to more stable learning and faster convergence. However, PPO may be less sample-efficient than other DRL algorithms, requiring more data to achieve similar performance.
Asynchronous Advantage Actor-Critic (A3C)
A3C is an actor-critic DRL algorithm that combines the benefits of value-based and policy-based methods. A3C utilizes multiple parallel agents to learn an optimal policy, making it highly suitable for trading problems with complex environments. A3C’s primary advantage is its ability to handle high-dimensional state and action spaces, as well as its robustness to noisy data. However, A3C may require more computational resources than other DRL algorithms due to its parallel nature.
Training and Evaluating Individual Models
To train individual DRL models, you can use historical financial data, such as price movements, volume, and technical indicators. It is essential to preprocess the data and split it into training, validation, and testing sets. During training, you can employ techniques such as early stopping and learning rate scheduling to prevent overfitting and improve generalization. After training, evaluate each model’s performance using appropriate metrics, such as the Sharpe ratio, Sortino ratio, or drawdown, to determine its suitability for inclusion in the ensemble.
By carefully selecting and training individual DRL models, you can create a diverse set of models that can be combined into an ensemble DRL trading strategy, harnessing the benefits of ensemble learning and improving overall performance.

Combining Individual Models into an Ensemble
Once you have trained individual deep reinforcement learning (DRL) models, the next step is to combine their predictions into an ensemble, harnessing the benefits of ensemble learning. Ensemble learning techniques, such as stacking, bagging, and boosting, can improve accuracy, reduce overfitting, and increase robustness in trading strategies.
Stacking
Stacking, or stacked generalization, involves training multiple base models and combining their predictions using a secondary model, known as a meta-learner or combiner. The base models are trained on the same dataset, while the meta-learner is trained on the outputs (predictions) of the base models. Stacking can improve accuracy by leveraging the strengths of each base model and reducing the impact of individual weaknesses. In the context of DRL trading strategies, stacking can help balance the trade-off between exploration and exploitation, leading to more robust and consistent performance.
Bagging
Bagging, or bootstrap aggregating, is a technique that trains multiple base models on different subsets of the training data, generated using bootstrap sampling. Each subset is created by randomly sampling the original dataset with replacement, allowing some data points to be included multiple times and others to be excluded. The base models’ predictions are then combined using a simple averaging or voting method. Bagging can reduce overfitting by encouraging diversity among the base models, as each model is exposed to different aspects of the data. In a DRL trading strategy, bagging can help improve generalization and stability, particularly in noisy or volatile financial markets.
Boosting
Boosting involves training multiple base models sequentially, with each subsequent model focusing on the errors of the previous models. The base models’ predictions are combined using a weighted sum or product, where the weights are adjusted based on each model’s performance. Boosting can improve accuracy by iteratively refining the predictions, focusing on the most challenging cases. In a DRL trading strategy, boosting can help enhance the overall performance by emphasizing the strengths of each base model and mitigating their weaknesses.
By combining individual DRL models into an ensemble using techniques such as stacking, bagging, and boosting, you can create a more accurate, robust, and consistent trading strategy. Ensemble learning can help mitigate the risks associated with relying on a single model, improving the overall performance and reliability of your trading system.

Designing a Backtesting Framework for Ensemble Deep Reinforcement Learning Trading Strategies
A crucial step in developing an ensemble deep reinforcement learning trading strategy is creating a robust backtesting framework. This framework allows you to evaluate the performance of your strategy using historical financial data, ensuring that it can effectively navigate real-world market conditions. Here are the key components of a backtesting framework for ensemble deep reinforcement learning trading strategies:
Data Preprocessing
Data preprocessing is the initial step in building a backtesting framework. It involves cleaning and transforming raw financial data into a format suitable for training and testing your ensemble deep reinforcement learning models. This may include handling missing values, normalizing or scaling features, and creating technical indicators or features based on historical price and volume data.
Performance Metrics
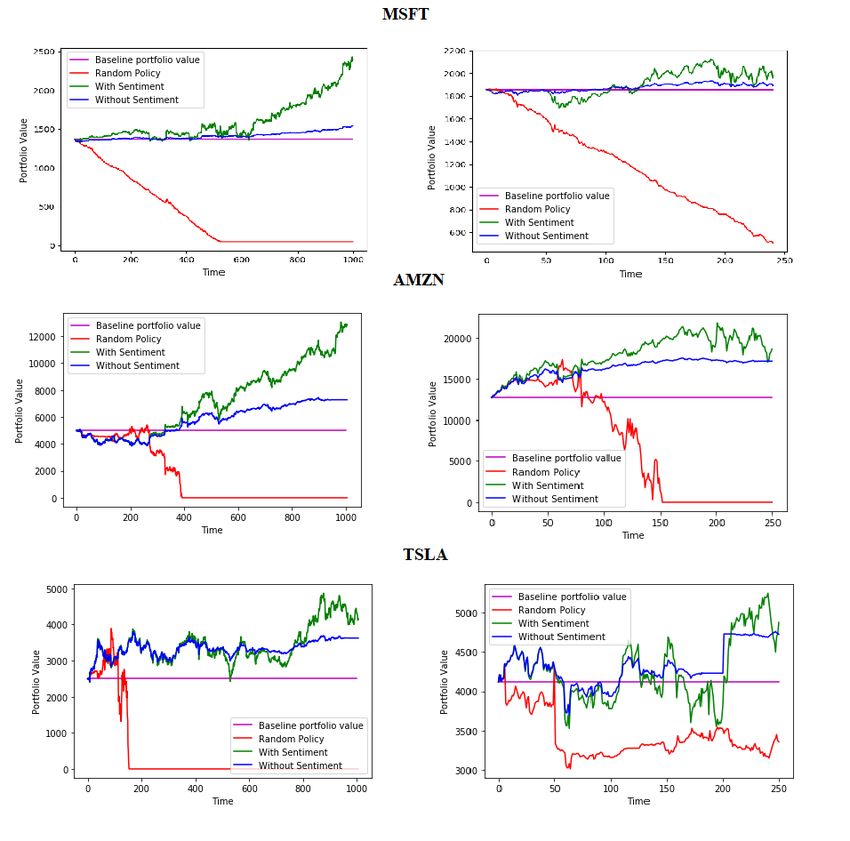
Selecting appropriate performance metrics is essential for evaluating the effectiveness of your ensemble deep reinforcement learning trading strategy. Common metrics include total return, annualized return, cumulative return, annualized volatility, Sharpe ratio, maximum drawdown, and sortino ratio. These metrics provide insights into the risk-adjusted performance of your strategy, helping you to compare and optimize different model configurations.
Statistical Analysis
Statistical analysis is necessary to assess the significance and reliability of your ensemble deep reinforcement learning trading strategy’s performance. This may involve conducting hypothesis tests, such as the t-test or the Mann-Whitney U test, to compare the performance of your strategy against a benchmark or a random strategy. Additionally, you can use techniques like bootstrapping or Monte Carlo simulations to estimate the distribution of your performance metrics and assess the robustness of your strategy.
Walk-Forward Optimization
Walk-forward optimization is a technique used to minimize overfitting and improve the generalization of your ensemble deep reinforcement learning trading strategy. It involves dividing your historical data into in-sample and out-of-sample periods. The in-sample period is used for training and optimizing your models, while the out-of-sample period is used for evaluating their performance. By iteratively shifting the in-sample and out-of-sample periods, you can assess how well your strategy can adapt to changing market conditions and avoid overfitting to historical data.
Designing a comprehensive backtesting framework is essential for evaluating and refining your ensemble deep reinforcement learning trading strategy. By incorporating data preprocessing, performance metrics, statistical analysis, and walk-forward optimization, you can create a robust and reliable system for testing and improving your strategy’s performance.
Applying Ensemble Deep Reinforcement Learning Trading Strategies to Real-World Scenarios
Ensemble deep reinforcement learning trading strategies have the potential to significantly impact various financial instruments, such as stocks, futures, and forex. By combining multiple deep reinforcement learning models, these strategies offer improved accuracy, reduced overfitting, and increased robustness compared to traditional single-model approaches. Here are some examples of how ensemble deep reinforcement learning trading strategies can be applied to real-world scenarios:
Stock Trading
Ensemble deep reinforcement learning trading strategies can be employed to optimize stock portfolios by determining the optimal buy, sell, or hold actions for individual stocks. By analyzing historical price and volume data, these strategies can learn to identify patterns and trends that indicate favorable trading opportunities. For instance, an ensemble deep reinforcement learning model can learn to recognize when a stock is undervalued or overvalued, allowing it to make informed trading decisions that maximize returns and minimize risk.
Futures Trading
Futures markets involve trading contracts for the future delivery of assets, such as commodities or financial instruments. Ensemble deep reinforcement learning trading strategies can be used to predict price movements in these markets, enabling traders to make profitable trades based on anticipated trends. By incorporating relevant market data, such as open interest and volume, these strategies can improve their accuracy and adapt to changing market conditions.
Forex Trading
Forex markets involve trading currencies, with traders attempting to profit from fluctuations in exchange rates. Ensemble deep reinforcement learning trading strategies can be applied to predict these fluctuations, allowing traders to make informed decisions about when to buy or sell specific currencies. By considering factors such as economic indicators, geopolitical events, and market sentiment, these strategies can improve their predictive power and generate consistent returns.
Implementing ensemble deep reinforcement learning trading strategies in real-world scenarios presents several challenges and limitations. These include the need for large amounts of historical financial data, the computational resources required to train and optimize multiple models, and the difficulty of adapting these strategies to rapidly changing market conditions. However, by addressing these challenges and leveraging the benefits of ensemble learning, traders can significantly improve their performance and gain a competitive edge in the financial markets.

Staying Ahead of the Curve: Emerging Trends and Future Directions
Ensemble deep reinforcement learning trading strategies have shown promising results in the financial industry, and recent advancements in this field continue to drive innovation and improvement. Here are some emerging trends and future directions in ensemble deep reinforcement learning and their implications for the trading industry:
Multi-Agent Systems
Multi-agent systems involve multiple learning agents interacting with each other and their environment to achieve a common goal. In the context of trading, multi-agent systems can be used to model the interactions between different traders, allowing for more accurate predictions of market dynamics. By incorporating multi-agent systems into ensemble deep reinforcement learning trading strategies, traders can improve their understanding of complex market behaviors and make more informed trading decisions.
Transfer Learning
Transfer learning involves applying knowledge gained from one task to another related task. In the context of trading, transfer learning can be used to apply the knowledge gained from training on one financial instrument to another related instrument. By leveraging transfer learning, traders can reduce the amount of data required to train effective trading strategies and improve their performance on new financial instruments.
Attention Mechanisms
Attention mechanisms allow deep learning models to focus on specific parts of the input data when making predictions. In the context of trading, attention mechanisms can be used to identify the most relevant features of financial data, such as price movements or economic indicators. By incorporating attention mechanisms into ensemble deep reinforcement learning trading strategies, traders can improve their accuracy and adaptability to changing market conditions.
As these trends continue to evolve, the trading industry can expect to see further improvements in the performance and applicability of ensemble deep reinforcement learning trading strategies. By staying up-to-date with these advancements and incorporating them into their trading strategies, traders can gain a competitive edge and maximize their returns in the financial markets.
How to Implement an Ensemble Deep Reinforcement Learning Trading Strategy: A Step-by-Step Guide
Implementing an ensemble deep reinforcement learning trading strategy can be a complex process, but by breaking it down into manageable steps, even novice traders can get started. Here is a step-by-step guide to implementing an ensemble deep reinforcement learning trading strategy:
Step 1: Selecting Appropriate Deep Learning Libraries
The first step in implementing an ensemble deep reinforcement learning trading strategy is to select appropriate deep learning libraries. Popular libraries include TensorFlow and PyTorch, both of which offer powerful tools for building and training deep learning models. When selecting a library, consider factors such as ease of use, compatibility with your existing infrastructure, and the availability of pre-built models and tools.
Step 2: Preprocessing Financial Data
Once you have selected a deep learning library, the next step is to preprocess your financial data. Preprocessing may include tasks such as cleaning the data, normalizing the data, and transforming the data into a format suitable for training deep learning models. When preprocessing financial data, it is important to consider factors such as the time frame of the data, the frequency of the data, and the relevant features of the data.
Step 3: Training Individual Models
After preprocessing the financial data, the next step is to train individual deep reinforcement learning models. This may involve selecting appropriate deep reinforcement learning algorithms, such as DQN, PPO, or A3C, and training the models using historical financial data. When training individual models, it is important to monitor their performance and adjust their parameters as needed to optimize their performance.
Step 4: Evaluating Individual Models
Once the individual models have been trained, the next step is to evaluate their performance. This may involve testing the models on a separate validation dataset and calculating performance metrics such as accuracy, precision, and recall. When evaluating individual models, it is important to consider factors such as their strengths and weaknesses, their generalizability to new data, and their robustness to noise and outliers.
Step 5: Combining Individual Models into an Ensemble
After evaluating the individual models, the next step is to combine them into an ensemble. This may involve techniques such as stacking, bagging, or boosting, and the choice of technique will depend on the specific requirements of the trading strategy. When combining individual models into an ensemble, it is important to consider factors such as the diversity of the models, the complementarity of their predictions, and the trade-off between accuracy and complexity.
Step 6: Backtesting the Ensemble Deep Reinforcement Learning Trading Strategy
Once the ensemble deep reinforcement learning trading strategy has been implemented, the final step is to backtest the strategy using historical financial data. This may involve techniques such as walk-forward optimization and statistical analysis, and the goal is to evaluate the performance of the strategy and identify any potential issues or limitations. When backtesting the ensemble deep reinforcement learning trading strategy, it is important to avoid overfitting and to consider factors such as the risk-reward trade-off and the scalability of the strategy.
By following these steps, traders can implement an ensemble deep reinforcement learning trading strategy that is accurate, robust, and adaptable to changing market conditions. With the right tools, data, and techniques, ensemble deep reinforcement learning trading strategies have the potential to revolutionize the trading industry and provide traders with a competitive edge in the financial markets.
