Deep Reinforcement Learning (DRL) vs. Supervised Machine Learning: Key Differences
Artificial intelligence (AI) has revolutionized various industries, offering innovative solutions to complex problems. Two primary AI model categories, Deep Reinforcement Learning (DRL) and supervised machine learning, have gained significant attention due to their prediction capabilities. While both model types have unique strengths, they cater to different use cases and environments. This article delves into the comparison of DRL and supervised machine learning prediction models, highlighting their key differences, applications, and evaluation techniques.

Click Image to Find Quantum Products

When to Use DRL Prediction Models
Deep Reinforcement Learning (DRL) models are particularly effective in dynamic, uncertain, or real-time environments where data variability is high. These models excel in situations where traditional supervised machine learning models struggle due to their inability to adapt to changing conditions. DRL models learn from the environment by continuously interacting with it, making them highly suitable for decision-making tasks and sequential data processing.
Some industries and use cases where DRL models have shown superior performance include:
- Autonomous vehicles: DRL models enable self-driving cars to navigate complex road networks, make real-time driving decisions, and adapt to changing traffic conditions.
- Gaming: DRL models have mastered various video games, such as Go, poker, and Atari games, by learning optimal strategies and adapting to opponents’ moves.
- Robotics: DRL models help robots learn intricate movements, manipulate objects, and adapt to new tasks with minimal human intervention.
- Stock market trading: DRL models can predict stock prices and optimize trading strategies based on real-time market data and historical trends.
- Personalized recommendations: DRL models can provide dynamic, context-aware recommendations in real-time, adapting to user preferences and behavior changes.
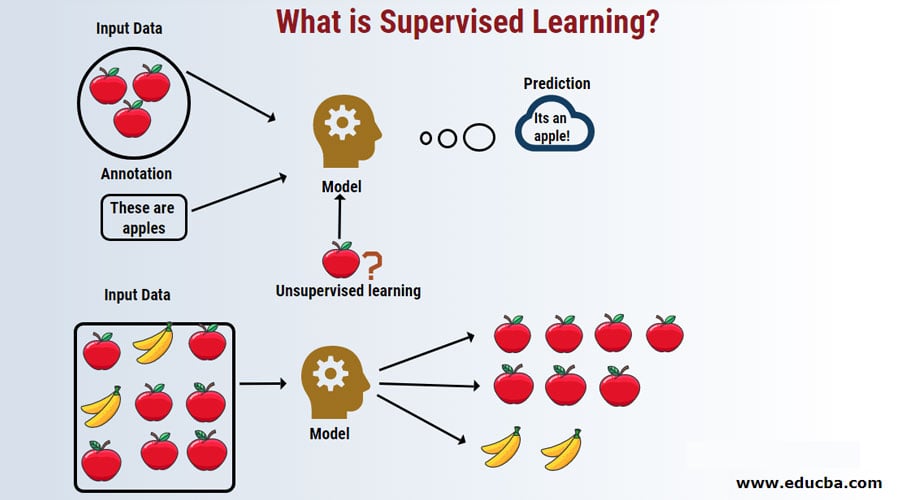
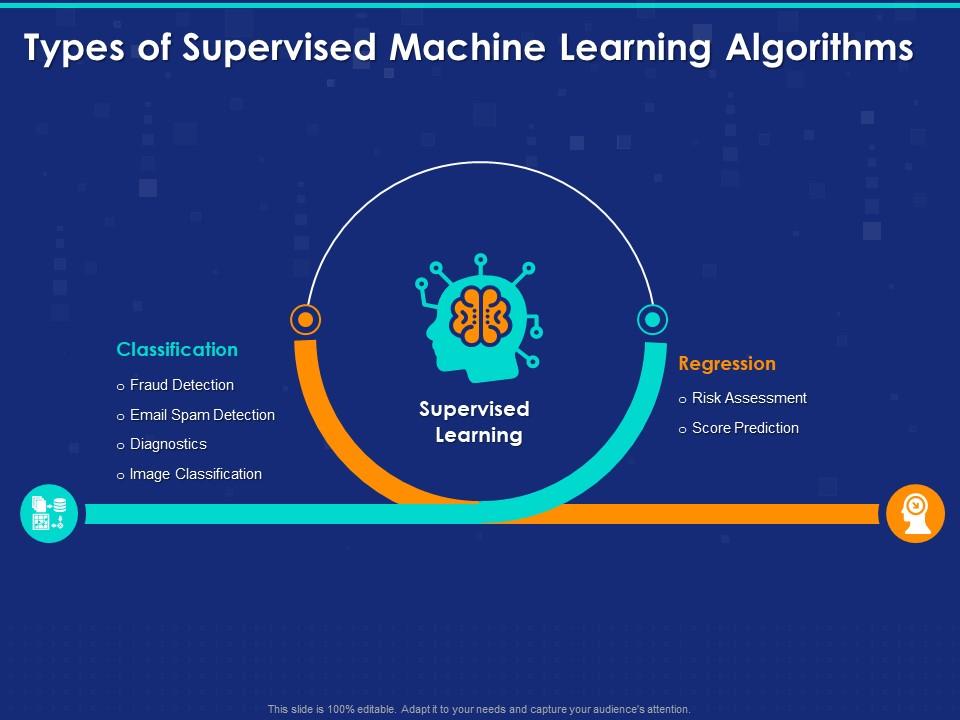
When to Use Supervised Machine Learning Prediction Models
Supervised machine learning models are best suited for static or low-variability environments where data distribution remains relatively consistent over time. These models are trained on labeled datasets and excel in situations where the underlying patterns and relationships between input features and output variables are stable. Supervised machine learning models are widely used in various industries and applications, such as:
- Image classification: Supervised machine learning models can accurately classify images based on their features, making them ideal for applications like medical imaging, facial recognition, and object detection.
- Sentiment analysis: Supervised machine learning models can analyze text data and determine the sentiment, enabling businesses to monitor customer feedback, social media conversations, and brand reputation.
- Fraud detection: Supervised machine learning models can identify unusual patterns and anomalies in financial transactions, helping banks and financial institutions detect and prevent fraud.
- Credit scoring: Supervised machine learning models can predict the creditworthiness of individuals based on their financial history, enabling lenders to make informed decisions.
- Predictive maintenance: Supervised machine learning models can predict equipment failures and maintenance needs based on historical data, helping organizations optimize their maintenance schedules and reduce downtime.

How to Evaluate and Compare DRL and Supervised Machine Learning Prediction Models
Evaluating and comparing the performance of DRL and supervised machine learning models is crucial for selecting the right prediction model for a specific use case. Various evaluation metrics and techniques can be employed to assess the effectiveness of these models. Here are some key aspects to consider:
- Performance metrics: Select appropriate evaluation metrics based on the problem type, such as accuracy, precision, recall, F1 score, or area under the ROC curve (AUC-ROC) for classification tasks, and mean squared error (MSE), mean absolute error (MAE), or R-squared for regression tasks.
- Cross-validation: Use cross-validation techniques to ensure the robustness and generalizability of the models. This involves dividing the dataset into multiple folds, training the model on different subsets, and testing it on the remaining data to assess its performance.
- Training time: Compare the training time of DRL and supervised machine learning models, as this can significantly impact the feasibility of deploying the models in real-world applications.
- Model interpretability: Consider the interpretability of the models, as supervised machine learning models are generally more interpretable than DRL models. However, recent advancements in explainable AI (XAI) have made DRL models more interpretable, enabling users to understand their decision-making processes.
- Data requirements: Assess the data requirements of both model types. Supervised machine learning models typically require large, labeled datasets, while DRL models can learn from unlabeled data and adapt to changing environments.
- Business objectives: Align the evaluation and comparison process with the specific use case, dataset, and business objectives. This will help ensure that the chosen model effectively addresses the problem at hand and delivers the desired outcomes.

Case Studies: Real-World Applications of DRL and Supervised Machine Learning Prediction Models
Exploring real-world applications of DRL and supervised machine learning prediction models can provide valuable insights into their performance, benefits, and limitations. Here are some examples:
Case Study 1: DRL in Autonomous Vehicles
Autonomous vehicles operate in dynamic, uncertain environments, making DRL models an ideal choice. DRL models enable these vehicles to learn from experience, adapt to new situations, and make real-time decisions. For instance, Wayve, a UK-based startup, uses DRL models to train autonomous vehicles to navigate complex urban environments, outperforming traditional rule-based systems in terms of adaptability and safety.
Case Study 2: Supervised Machine Learning in Credit Risk Assessment
Supervised machine learning models excel in static or low-variability environments, such as credit risk assessment. By analyzing historical data, these models can predict the likelihood of default, enabling financial institutions to make informed lending decisions. For example, ZestFinance, a financial technology company, uses gradient boosting machines (GBMs) to assess credit risk, reducing the risk of default by up to 30% compared to traditional models.
Case Study 3: DRL in Personalized Recommendation Systems
DRL models can also be applied to personalized recommendation systems, where user preferences and contexts are constantly changing. DRL models can learn from user interactions and adapt recommendations in real-time, enhancing user engagement and satisfaction. A notable example is Netflix’s use of DRL models to optimize its recommendation engine, resulting in increased viewer retention and content consumption.
Case Study 4: Supervised Machine Learning in Medical Diagnostics
Supervised machine learning models have been widely adopted in medical diagnostics, where they can analyze large datasets of patient records and medical images to identify patterns and make accurate predictions. For instance, Google’s DeepMind uses convolutional neural networks (CNNs) to detect early-stage age-related macular degeneration (AMD) and diabetic retinopathy, achieving accuracy levels comparable to or surpassing those of human experts.
These case studies demonstrate the potential of DRL and supervised machine learning prediction models in various industries and applications. However, it is essential to consider the specific use case, dataset, and business objectives when selecting a prediction model to ensure optimal performance and value.
Future Trends and Research Directions in DRL and Supervised Machine Learning Prediction Models
As DRL and supervised machine learning prediction models continue to evolve, several emerging trends and research directions are shaping their future. These advancements aim to improve model architectures, training techniques, and applications, enhancing their predictive capabilities and value in various industries.
Advancements in Model Architectures
Researchers are exploring new model architectures to address the limitations of existing DRL and supervised machine learning models. For instance, the integration of attention mechanisms in transformer-based models has shown promising results in handling long-range dependencies and improving interpretability. Additionally, the development of graph neural networks (GNNs) has opened up new possibilities for modeling complex, structured data in various domains.
Improved Training Techniques
Training techniques for DRL and supervised machine learning models are also advancing, focusing on addressing challenges such as data scarcity, non-stationarity, and catastrophic forgetting. Meta-learning, also known as “learning to learn,” has emerged as a promising approach for improving model generalization and adaptability in new environments. Furthermore, reinforcement learning with a human-in-the-loop (HIL) has shown potential in addressing safety concerns and facilitating more efficient model training.
Expanding Applications
DRL and supervised machine learning models are being applied to an increasing number of industries and use cases, from autonomous systems and robotics to finance and healthcare. As these models become more sophisticated and adaptable, they are expected to play a crucial role in addressing pressing societal challenges, such as climate change, healthcare disparities, and sustainable energy.
In conclusion, the future of DRL and supervised machine learning prediction models looks promising, with advancements in model architectures, training techniques, and applications. By staying updated on these developments, industry professionals can leverage these technologies to drive innovation, improve decision-making, and create value in their respective domains.

Choosing the Right Prediction Model: Best Practices and Considerations
When deciding between DRL and supervised machine learning prediction models, it is crucial to consider several factors to ensure optimal performance and value for your specific use case, dataset, and business objectives. By understanding the unique characteristics and strengths of each model category, you can make informed decisions and maximize the potential benefits for your organization.
Understanding Your Use Case
Assess the dynamic nature of your environment and the level of uncertainty involved. DRL models are more suitable for handling complex, dynamic systems with high uncertainty and real-time decision-making requirements. In contrast, supervised machine learning models are better suited for static or low-variability environments where historical data can effectively inform future predictions.
Evaluating Your Dataset
Consider the size, quality, and structure of your dataset. DRL models typically require large amounts of data and may struggle with small or noisy datasets. Supervised machine learning models can perform well with smaller datasets but may have limited adaptability in dynamic environments. Additionally, evaluate whether your data is structured or unstructured, as this can influence the choice of model architecture.
Defining Business Objectives
Clearly outline your business objectives and the specific outcomes you aim to achieve with your prediction model. This will help you determine the appropriate evaluation metrics and assess the trade-offs between model complexity, performance, and interpretability.
Selecting Evaluation Metrics
Choose evaluation metrics that align with your business objectives and provide a comprehensive assessment of model performance. For DRL models, consider metrics such as average reward, episode length, and success rate. For supervised machine learning models, common metrics include accuracy, precision, recall, and F1 score. Regularly monitor and update these metrics to ensure your model continues to meet your performance expectations.
Iterative Model Improvement
Lastly, embrace an iterative approach to model improvement, incorporating feedback loops and continuous learning to refine your prediction models over time. By staying updated on the latest advancements in DRL and supervised machine learning, you can adapt your models to new challenges, improve performance, and unlock additional value for your organization.
Conclusion: The Continuing Evolution of DRL and Supervised Machine Learning Prediction Models
In conclusion, DRL and supervised machine learning prediction models each offer unique advantages and applications, making them valuable tools for various industries and use cases. By understanding their key differences, evaluating performance metrics, and considering specific use cases, datasets, and business objectives, organizations can make informed decisions when selecting a prediction model. Moreover, staying updated on emerging trends and research directions in DRL and supervised machine learning will enable businesses to adapt their models to new challenges, improve performance, and unlock additional value.
As the field of artificial intelligence continues to advance, it is crucial for organizations to explore and harness the potential of DRL and supervised machine learning prediction models. By embracing these technologies and considering their specific needs and objectives, businesses can drive innovation, enhance decision-making, and ultimately, gain a competitive edge in their respective industries.