The Power of Reinforcement Learning in Stock Trading
Reinforcement learning (RL) is a type of machine learning where an agent learns to make decisions by interacting with an environment to maximize a reward signal. In the context of stock trading, RL can be used to develop a trading agent that learns to make profitable trades by observing market data and receiving feedback in the form of rewards or penalties. This approach has the potential to outperform traditional trading strategies by continuously adapting to changing market conditions and optimizing trading decisions.

Click Image to Find Quantum Products
Double Q Learning and Double Deep Q Networks (DDQNs) are two advanced RL techniques that have shown promising results in stock trading applications. These methods aim to address the challenges of traditional Q-learning, such as overestimation of action values and the need for function approximation when dealing with high-dimensional inputs like stock market data.
Double Q Learning involves maintaining two separate Q-value functions, allowing for more accurate action value estimates and reducing overestimation bias. On the other hand, DDQNs combine deep learning with RL, enabling the agent to learn from raw inputs like stock prices, volumes, and other technical indicators. By using neural networks as function approximators, DDQNs can handle high-dimensional inputs and extract meaningful features for trading decisions.
By harnessing the power of Double Q Learning and DDQNs, traders can develop more sophisticated and profitable trading strategies. These RL techniques can help optimize trading decisions, manage risk, and adapt to changing market conditions, ultimately contributing to the profitability of stock trading using Python.
Double Q Learning: A Promising Approach to Stock Trading
Double Q Learning is a reinforcement learning technique that addresses the overestimation bias present in traditional Q-learning methods. In stock trading, this approach can help optimize trading decisions and maximize profits by providing more accurate action value estimates.
The main idea behind Double Q Learning is to maintain two separate Q-value functions, Q1 and Q2, which are used to estimate the action values for a given state. At each time step t, the agent selects the action a\_t using Q1 and evaluates the action value using Q2. This process is then reversed, with the action being selected using Q2 and its value being estimated using Q1. The agent then updates the Q-value function with the lower of the two estimated action values, ensuring that overestimation bias is reduced.
Applying Double Q Learning to stock trading involves using historical market data to train the agent. The agent observes the current state of the market, represented by various features such as stock prices, volumes, and technical indicators, and selects an action, such as buying, selling, or holding a stock. The environment then transitions to a new state, and the agent receives a reward or penalty based on the profit or loss generated by the action. The Q-value functions are then updated based on the observed transition and reward.
Double Q Learning has several advantages over traditional trading strategies. It can adapt to changing market conditions by continuously updating its Q-value functions based on new data. Additionally, it can handle high-dimensional inputs like stock market data by using function approximation techniques, such as neural networks. This allows the agent to learn complex relationships between market features and profitable trading actions.
By harnessing the power of Double Q Learning, traders can develop more sophisticated and profitable trading strategies. This approach can help optimize trading decisions, manage risk, and adapt to changing market conditions, ultimately contributing to the profitability of stock trading using Python.
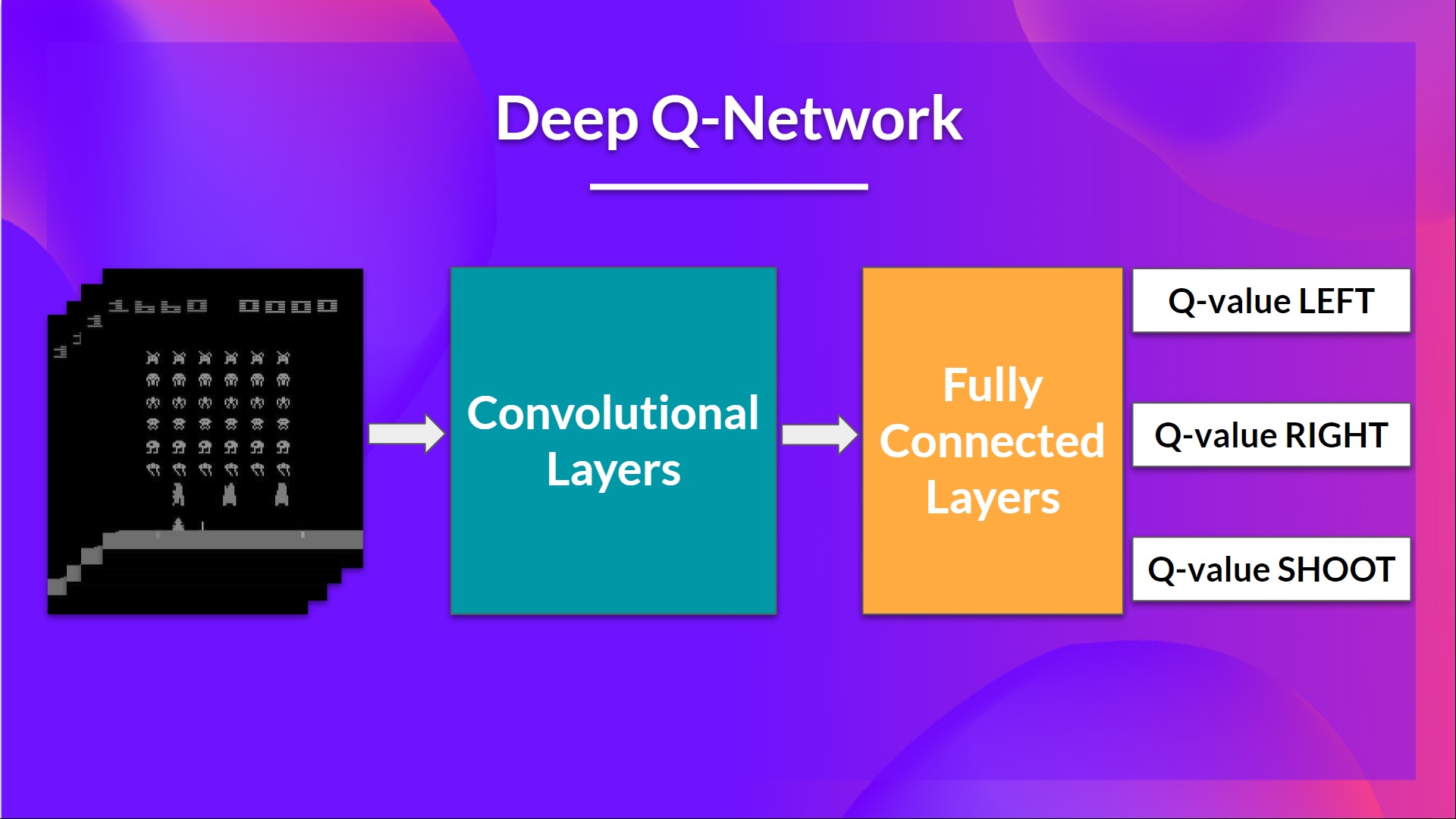
Harnessing the Power of Deep Learning: Double Deep Q Networks
Double Deep Q Networks (DQNs) are a more advanced approach to reinforcement learning, combining deep learning with Q-learning to improve stock trading performance. By using neural networks to approximate the Q-value function, DQNs can handle high-dimensional inputs and learn complex relationships between market features and profitable trading actions.
A DQN consists of two main components: a deep neural network and a replay memory. The deep neural network is used to estimate the Q-value function, while the replay memory stores past experiences, allowing the network to learn from a diverse set of data. At each time step t, the agent observes the current state of the market, selects an action, and receives a reward or penalty. The transition (s\_t, a\_t, r\_t, s\_{t+1}) is then stored in the replay memory. During training, the network randomly samples mini-batches of transitions from the replay memory and updates its weights to minimize the loss function.
In stock trading, DQNs can be used to learn a policy that maximizes profits by optimizing trading decisions. By using historical market data to train the network, the agent can learn to identify profitable trading opportunities and adapt to changing market conditions. The DQN can handle high-dimensional inputs, such as stock prices, volumes, and technical indicators, and learn complex relationships between these features and profitable trading actions.
DQNs have several advantages over traditional trading strategies. They can adapt to changing market conditions by continuously updating their weights based on new data. Additionally, they can handle high-dimensional inputs and learn complex relationships between market features and profitable trading actions. This allows the agent to learn more sophisticated trading strategies that can improve profitability.
By harnessing the power of DQNs, traders can develop more sophisticated and profitable trading strategies. This approach can help optimize trading decisions, manage risk, and adapt to changing market conditions, ultimately contributing to the profitability of stock trading using Python.

Getting Started with Python: Setting Up Your Development Environment
To start building a Double Q Learning trading agent using Python, you need to set up a development environment. This section provides a step-by-step guide on how to install Python, necessary libraries, and tools for stock trading.
First, download and install Python from the official website (https://www.python.org/downloads/). Choose the latest stable version and select the option “Add Python to PATH” during installation. This will ensure that Python is properly configured in your system.
Next, install the necessary libraries for stock trading and reinforcement learning. Open a command prompt or terminal and run the following commands:
pip install numpy pandas matplotlib keras tensorflow pip install gym stable_baselines These libraries provide the necessary tools for data manipulation, visualization, deep learning, and reinforcement learning. In particular, gym is a popular library for developing and testing reinforcement learning algorithms, while stable_baselines is a library that provides stable implementations of various reinforcement learning algorithms, including Double Q Learning and Double Deep Q Networks.
After installing the necessary libraries, you can start building your Double Q Learning trading agent using Python. In the next section, we will walk through the process of building a Double Q Learning trading agent, explaining the code structure, components, and functions.

Building a Double Q Learning Trading Agent with Python
Now that you have set up your Python development environment, it’s time to build a Double Q Learning trading agent. In this section, we will walk through the process of building a Double Q Learning trading agent using Python, explaining the code structure, components, and functions.
First, let’s define the components of a Double Q Learning trading agent. A Double Q Learning trading agent consists of the following components:
environment: The stock market environment where the trading agent interacts with.state: The current state of the stock market, represented as a set of features.action: The trading action taken by the trading agent, such as buying, selling, or holding.reward: The reward received by the trading agent after taking an action, such as the profit or loss from a trade.Q-table: A table that stores the expected cumulative reward for each state-action pair.policy: A function that maps each state to an action based on the Q-table.
Next, let’s implement these components in Python. First, we need to define the environment. We will use the gym library to define the environment as a Markov Decision Process (MDP). Here’s an example of how to define a stock trading environment in Python:
import gym env = gym.make('StockTrading-v0')
In this example, we use the gym.make() function to create a stock trading environment. The environment is defined as a Markov Decision Process (MDP), where the state is represented as a set of features, such as the current price, volume, and moving averages. The action is defined as a trading action, such as buying, selling, or holding. The reward is defined as the profit or loss from a trade.
Next, we need to implement the Q-table and the policy. We will use a dictionary to store the Q-table, where the keys are the state-action pairs and the values are the expected cumulative rewards. Here’s an example of how to initialize the Q-table in Python:
Q = {} for state in env.observation_space: for action in env.action_space: Q[(state, action)] = 0 In this example, we initialize the Q-table as an empty dictionary. We then iterate over all possible state-action pairs and initialize their expected cumulative rewards to zero.
Finally, we need to implement the policy. We will use an epsilon-greedy policy, where the trading agent chooses the action with the highest expected cumulative reward with probability 1 - epsilon, and chooses a random action with probability epsilon. Here’s an example of how to implement the epsilon-greedy policy in Python:
epsilon = 0.1 state = env.reset() while True: if np.random.random() < epsilon: action = env.action_space.sample() else: action = max(Q[(state, a)] for a in env.action_space) state, reward, done, _ = env.step(action) Q[(state, action)] += alpha * (reward + discount * max(Q[(state_, a)] for a in env.action_space) - Q[(state, action)]) if done: break In this example, we implement the epsilon-greedy policy using the numpy.random.random() function to generate a random number between 0 and 1. If the random number is less than epsilon, the trading agent chooses a random action. Otherwise, the trading agent chooses the action with the highest expected cumulative reward. The trading agent then updates the Q-table based on the reward received and the expected cumulative rewards of the new state.
By following these steps, you can build a Double Q Learning trading agent using Python. In the next section, we will discuss how to enhance the performance of the trading agent by implementing Double Deep Q Networks in Python.
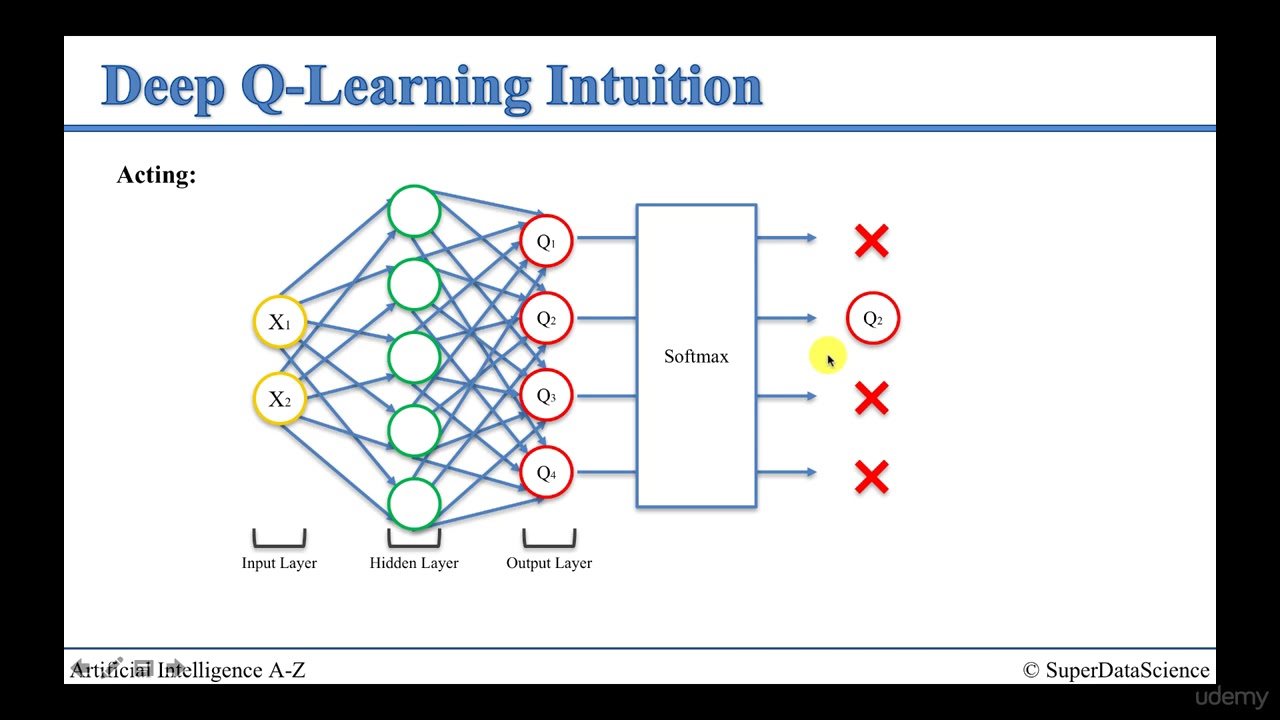
Enhancing Performance: Implementing Double Deep Q Networks in Python
Double Deep Q Networks (DDQNs) are a more advanced approach to reinforcement learning, combining deep learning with reinforcement learning to optimize trading decisions and maximize profits in stock trading. In this section, we will guide you through the implementation of Double Deep Q Networks in Python.
DDQNs are an extension of Deep Q Networks (DQNs), which use a neural network to approximate the Q-value function. DDQNs, on the other hand, use two neural networks to decouple the action selection and action evaluation, reducing the overestimation bias present in DQNs. This results in more accurate Q-value estimates and improved trading performance.
To implement DDQNs in Python, we will use the keras library to build the neural network. Here’s an example of how to define the neural network architecture in Python:
model = Sequential() model.add(Dense(256, input_dim=env.observation_space.shape[0], activation='relu')) model.add(Dense(256, activation='relu')) model.add(Dense(len(env.action_space), activation='linear')) In this example, we define a neural network with two hidden layers, each with 256 neurons. The input dimension of the neural network is set to the number of features in the state space. The output dimension of the neural network is set to the number of actions in the action space.
Next, we need to implement the training loop for the DDQN. We will use the experience replay technique to train the DDQN, where we store past experiences in a buffer and sample from the buffer to train the neural network. Here’s an example of how to implement the training loop in Python:
experience = deque(maxlen=experience_buffer_size) optimizer = Adam(lr=learning_rate) model.compile(loss='mse', optimizer=optimizer) epsilon = 1.0 epsilon_min = 0.01 epsilon_decay = 0.995 batch_size = 32 train_start =
Optimizing Your Trading Strategy: Tips and Best Practices
Double Q Learning and Double Deep Q Networks have the potential to revolutionize stock trading, but it’s important to follow best practices to optimize your trading strategy. Here are some tips and best practices for using Double Q Learning and Double Deep Q Networks in stock trading:
- Risk Management: It’s essential to manage risk when trading stocks. Set stop-loss orders to limit potential losses, and diversify your portfolio to spread risk. Use position sizing to control the amount of capital at risk in each trade.
- Backtesting: Backtest your trading strategy using historical data to evaluate its performance. This will help you identify any issues and make adjustments before trading with real money. Be sure to use realistic data and consider transaction costs and slippage.
- Continuous Improvement: Continuously monitor and improve your trading strategy. Keep up-to-date with market conditions and adjust your strategy accordingly. Consider using techniques like online learning to update your model in real-time.
- Feature Engineering: Carefully select and engineer the features used in your model. Consider technical indicators, fundamental data, and alternative data sources. Use feature selection techniques to identify the most relevant features and reduce overfitting.
- Hyperparameter Tuning: Tune the hyperparameters of your model to optimize performance. Use techniques like grid search, random search, or Bayesian optimization to find the best hyperparameters.
- Generalization: Ensure that your model generalizes well to new data. Use techniques like cross-validation and regularization to prevent overfitting. Consider using techniques like domain adaptation to adapt your model to new market conditions.
By following these tips and best practices, you can optimize your trading strategy using Double Q Learning and Double Deep Q Networks in stock trading. With careful planning and execution, you can improve trading performance and maximize profits.
Real-World Applications and Success Stories
Double Q Learning and Double Deep Q Networks have been successfully applied to stock trading, generating profits and improving trading performance. Here are some real-world applications and success stories:
- AQR: AQR, a quantitative investment firm, has used reinforcement learning techniques, including Double Q Learning, to optimize trading strategies. According to a research paper published by AQR, reinforcement learning has the potential to improve trading performance by reducing transaction costs and maximizing alpha.
- BlackRock: BlackRock, the world’s largest asset manager, has also explored the use of reinforcement learning in stock trading. In a research paper, BlackRock’s scientists discussed the potential of Double Deep Q Networks to improve trading performance by learning from experience and adapting to new market conditions.
- JPMorgan Chase: JPMorgan Chase, a leading global financial services firm, has used reinforcement learning techniques to optimize trading strategies. In a research paper, JPMorgan’s scientists discussed the potential of Double Q Learning to improve trading performance by learning from experience and adapting to new market conditions.
These success stories demonstrate the potential of Double Q Learning and Double Deep Q Networks in stock trading. By learning from experience and adapting to new market conditions, these techniques can generate profits and improve trading performance. However, it’s important to note that these techniques require careful planning and execution, as well as continuous monitoring and improvement.