Section 1: Foundations of Deep Reinforcement Learning
Deep reinforcement learning (DRL), a subfield of machine learning, combines artificial neural networks with traditional reinforcement learning techniques. These powerful algorithms enable agents to learn optimal behaviors through trial and error interactions with dynamic environments. By harnessing the ability to generalize patterns across diverse scenarios, DRL has demonstrated remarkable successes in complex tasks ranging from game playing to robotic control.

Click Image to Find Quantum Products
At its core, DRL revolves around three fundamental components:
- Value Estimation: Quantifying the expected cumulative reward associated with particular states or state-action pairs.
- Policy Optimization: Determining the ideal strategy governing agent behavior given environmental conditions.
- Exploration vs Exploitation Tradeoff: Balancing the need to maximize immediate rewards versus gathering information for improved performance in subsequent encounters.
These foundational elements lay the groundwork for understanding sophisticated DRL architectures and their applications to trading orderbooks. Mastery of these basics enables practitioners to construct more nuanced models capable of navigating intricate financial markets effectively.

Section 2: Key Deep Reinforcement Learning Techniques
In this section, we delve into prominent DRL techniques that have garnered significant attention due to their effectiveness and versatility. Familiarizing oneself with these methods is crucial for leveraging DRL’s full potential in tackling challenging problems like algorithmic trading orderbooks.
- Q-Learning: This approach focuses on estimating action values—the expected returns of taking specific actions under certain circumstances. Traditional Q-learning employs tabular representations but struggles with high-dimensional spaces. Combined with deep neural networks, however, it can handle continuous state and action spaces efficiently.
- Actor-Critic Models: Actor-critic methods consist of two primary components: an ‘actor,’ responsible for selecting actions, and a ‘critic,’ accountable for evaluating those choices. Through iterative interaction, both entities improve concurrently, leading to enhanced overall performance compared to isolated training schemes.
- Policy Gradient Algorithms: Policy gradients directly optimize policies instead of indirectly via value functions. They are particularly well-suited for handling stochastic and continuous action spaces. Common variations include REINFORCE, advantage actor-critic (A2C), and asynchronous advantage actor-critic (A3C).
Selecting appropriate DRL techniques depends largely on task-specific factors, such as environment complexity, available computational resources, and desired convergence rates. Developing proficiency in applying these varied methods equips researchers and practitioners alike with valuable tools necessary for excelling in the realm of algorithmic trading orderbooks.
}

Section 3: Integrating Deep Reinforcement Learning with Trading Orderbooks
Having established foundational understanding and familiarity with key DRL techniques, let us now explore how they can be effectively integrated with trading orderbooks. Successful integration hinges upon careful consideration of several critical aspects.
- State Representation: Designing informative yet compact state representations poses a challenge. Relevant features may include price levels, bid-ask spreads, volume imbalances, and historical market trends. Balancing dimensionality against expressiveness remains vital for ensuring efficient learning processes.
- Action Space Formulation: Determining feasible actions forms another integral component. Possibilities range from placing limit orders at discrete price intervals to continuously adjusting positions according to dynamic risk management strategies.
- Reward Function Engineering: Rewards should accurately reflect desirable outcomes while discouraging undesired behavior. Typical reward structures encompass profit maximization, transaction cost minimization, and risk mitigation through penalties imposed on excessive volatility exposure.
To illustrate these concepts, consider a hypothetical example where an agent learns to execute trades dynamically based on streaming order book updates. Initially, the agent observes current mid prices and corresponding volumes across multiple assets. Subsequently, it selects one asset and places either buy or sell limit orders at specified price offsets relative to prevailing mid prices. Upon completion of each transaction, the agent receives feedback in terms of realized profits or losses, accounting for slippage costs and other fees.
Through repeated interactions, the DRL algorithm incrementally refines its decision-making process, balancing short-term rewards against long-term return expectations. By adhering to sound design principles and employing judicious fine-tuning, practitioners can successfully integrate DRL algorithms with trading orderbooks, thereby unlocking novel avenues for enhancing alpha generation and risk management capabilities.

Section 4: How To Implement Deep Reinforcement Learning for Trading Orderbooks Using Python
In this section, we delve into the practical implementation details of combining deep reinforcement learning (DRL) with trading orderbooks utilizing Python. Leveraging powerful open-source libraries like TensorFlow and Keras simplifies the development process significantly.
Step 1: Set Up Your Environment
Initiate by installing necessary packages via pip or conda, incorporating TensorFlow, Keras, NumPy, Pandas, and Matplotlib among others. Organizing your project directory structure efficiently is also crucial, separating source files, dataset storage, and visualizations.
Step 2: Prepare Data Structures
Define relevant classes representing core components of trading orderbooks, such as OrderBookEntry, LimitOrder, MarketOrder, and Trade. These abstractions facilitate seamless manipulation and analysis of complex financial data streams.
Step 3: Establish State Spaces & Action Spaces
Formulate appropriate state spaces encapsulating pertinent information about evolving market conditions and action spaces defining available strategic maneuvers. This stage demands meticulous attention since well-crafted state and action spaces directly influence learning efficiency and solution quality.
Step 4: Instantiate DRL Agents
Create instances of desired DRL agents, selecting from options such as Deep Q Network (DQN), Advantage Actor Critic (A2C), or Proximal Policy Optimization (PPO). Customize architectural parameters, loss functions, optimizers, memory capacities, and exploration policies accordingly.
Step 5: Train Agent Models
Train agent models iteratively over numerous episodes, intermittently evaluating performance metrics and applying early stopping rules if convergence criteria are satisfied prematurely. Store trained weights periodically during training to enable resuming interrupted sessions effortlessly.
Step 6: Test & Evaluate Performance
After completing the training phase, assess the efficacy of learned strategies under varying scenarios, simulating real-world execution uncertainties and adversarial environments. Visualize results using intuitive plots depicting cumulative returns, win rates, Sharpe ratios, etc., providing insights into overall system effectiveness.
Step 7: Deployment Considerations
Lastly, address production readiness concerns, considering factors like computational resource allocation, latency tolerance, fault tolerance, scalability, regulatory compliance, and security measures before deploying the final product in live markets.
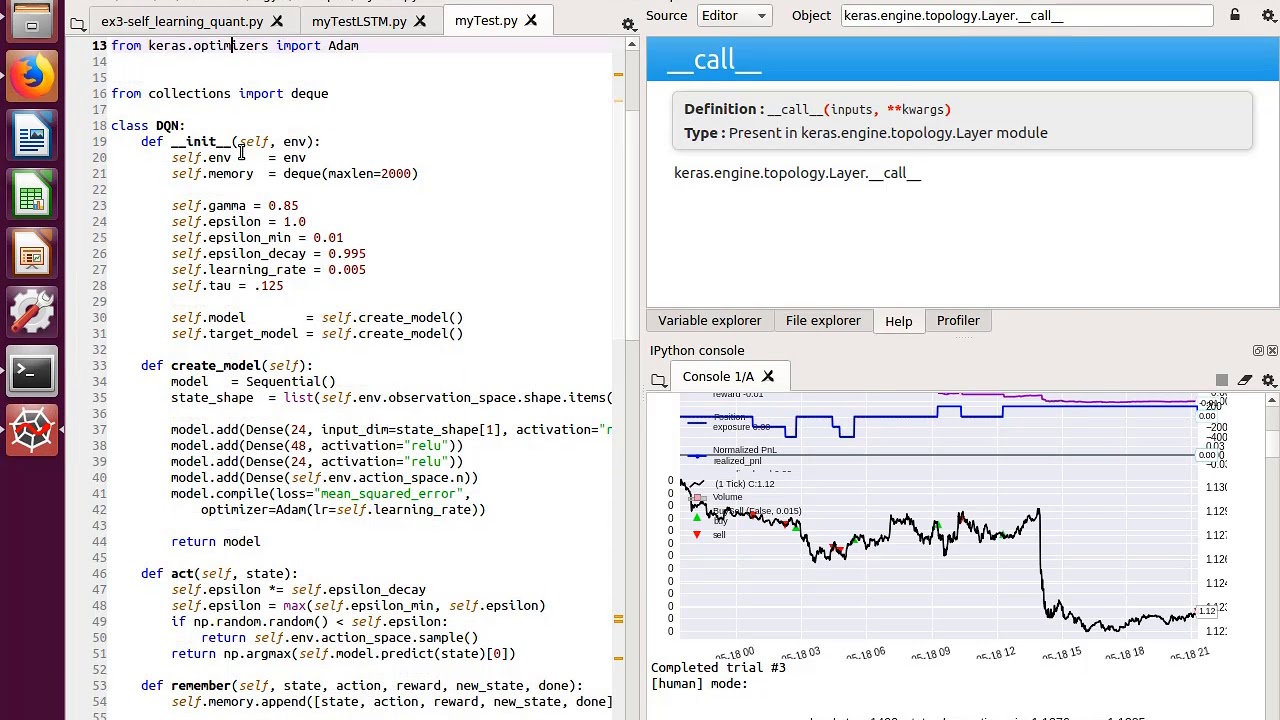
Section 5: Curated Sample Codes for Trading Orderbooks
Deep reinforcement learning has gained significant traction in recent years due to its applicability across diverse domains, particularly in algorithmic trading orderbooks. As aspiring practitioners venture deeper into this fascinating intersection, they often seek guidance through accessible yet informative resources. Herein, we present curated sample codes specifically designed to elucidate the intricacies of deep reinforcement learning for trading orderbooks.
These samples encompass fundamental aspects of deep reinforcement learning, illustrating how various algorithms interact with simulated trading environments. By examining these exemplars, readers can glean valuable insights regarding the design choices, implementation nuances, and fine-tuning requirements inherent in constructing proficient trading agents capable of navigating dynamic orderbook landscapes.
Example 1: Deep Q-Networks (DQNs)
Our inaugural example delves into the realm of Deep Q-Networks, which deftly combine classical Q-learning with convolutional neural networks (CNNs) to approximate optimal actions given specific states. Within the context of trading orderbooks, DQNs prove especially adept at discerning patterns amidst high-dimensional input features, ultimately facilitating informed decisions concerning order placement and execution.
Example 2: Proximal Policy Optimization (PPO)
Next, we explore Proximal Policy Optimization, an actor-critic method renowned for its stability and ease of use compared to other policy gradient algorithms. PPO strikes an equilibrium between sample complexity and asymptotic performance, rendering it an ideal choice for tackling challenging trading problems characterized by continuous state and action spaces.
Example 3: Multi-Agent Systems
Finally, our collection culminates with multi-agent systems, where multiple intelligent entities engage in cooperative or competitive interactions within shared environments. Such setups mirror realistic financial ecosystems teeming with heterogeneous actors, each armed with distinct goals, constraints, and behaviors. Investigating these sophisticated dynamics enables researchers to devise more nuanced trading strategies attuned to prevailing market conditions.
By perusing these carefully selected sample codes, novice and experienced learners alike stand to benefit immensely from the distilled wisdom contained therein. Armed with this enhanced understanding, they may then embark upon crafting bespoke deep reinforcement learning solutions tailored explicitly to trading orderbooks, thereby unlocking untapped sources of alpha and propelling themselves ahead of the competition.

Section 5: Curated Sample Codes for Trading Orderbooks
In the quest to harness the prowess of deep reinforcement learning for trading orderbooks, developers are constantly seeking practical resources that facilitate efficient knowledge transfer and skill acquisition. This section caters to this demand by presenting a selection of meticulously chosen sample codes, designed to illuminate various facets of deploying DRL algorithms in financial markets.
The following examples encapsulate crucial elements of deep reinforcement learning, shedding light on different algorithms’ interaction with simulated trading environments. These vignettes offer valuable insights into design considerations, implementation subtleties, and fine-tuning necessities involved in creating astute trading agents primed to excel within dynamic order book landscapes.
Example 1: Double Deep Q-Networks (DDQN)
Our maiden entry introduces Double Deep Q-Networks, an extension of standard DQNs that addresses overestimation biases prevalent in Q-value estimates. Financial time series analysis benefits significantly from DDQNs’ ability to mitigate such issues, leading to improved performance and heightened reliability in real-world applications.
Example 2: Advantage Actor Critic (A2C) Method
Next, we turn our attention towards the Advantage Actor Critic method, a powerful policy gradient technique combining the strengths of both value-based and policy-based approaches. Its innate suitability for handling continuous action spaces makes A2C particularly appealing for solving complex trading tasks involving myriad strategic options.
Example 3: Monte Carlo Tree Search (MCTS)
Lastly, our compilation includes Monte Carlo Tree Search, an iterative sampling algorithm employed extensively in games and planning scenarios. MCTS proves instrumental in optimizing trading strategies under uncertainty, enabling agents to navigate stochastic environments effectively and adapt swiftly to evolving market conditions.
By scrutinizing these well-chosen sample codes, both neophytes and seasoned practitioners stand to gain profound insights into the art of applying deep reinforcement learning for trading orderbooks. Leveraging this augmented comprehension, they can proceed to architect tailor-made DRL solutions geared towards specific challenges posed by trading orderbooks, thus unlocking novel avenues for generating alpha and securing a competitive edge.
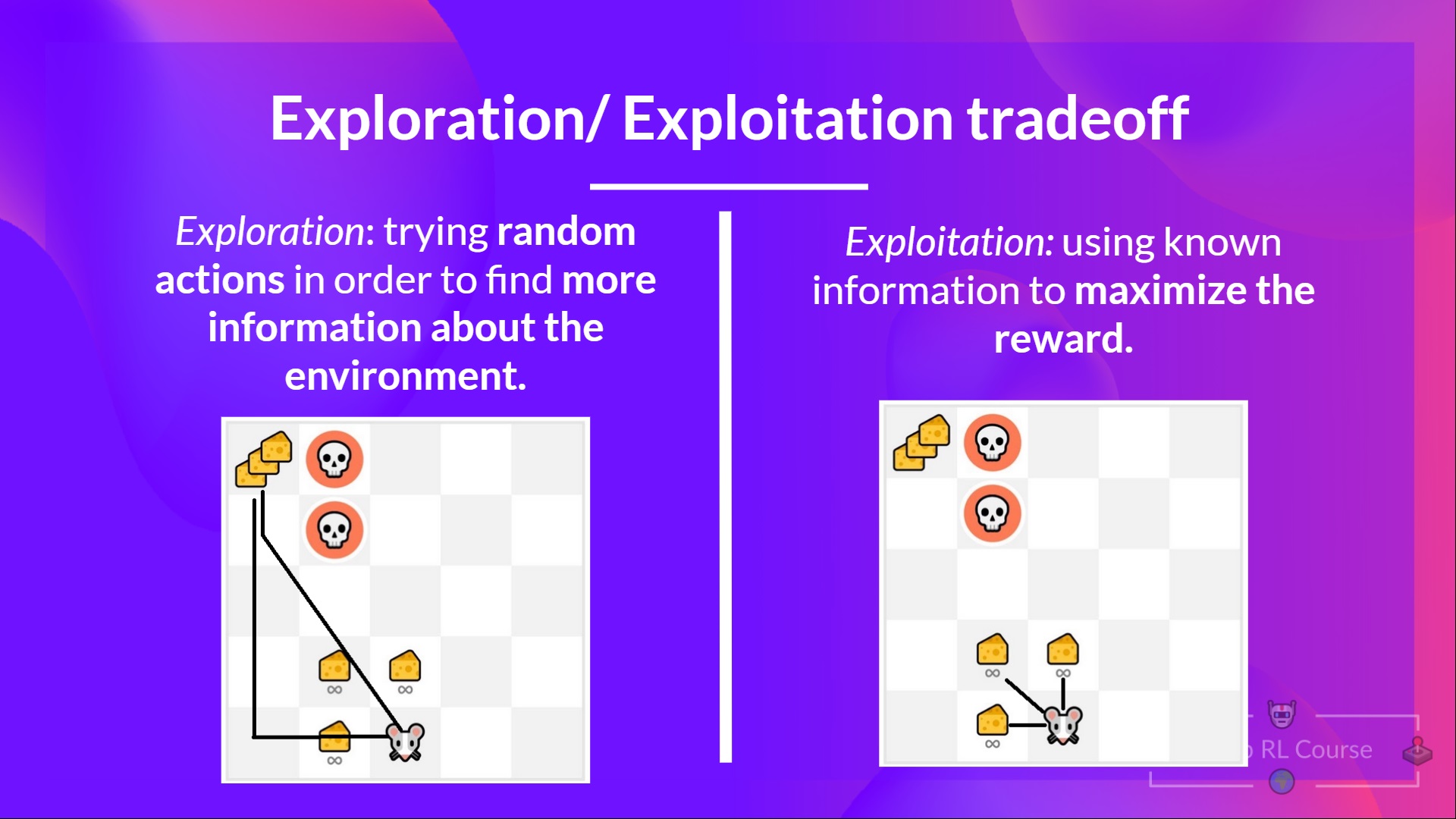
Conclusion: Unlocking the Potential of Deep Reinforcement Learning in Algorithmic Trading
Throughout this extensive guide, we have delved into the intricate world of deep reinforcement learning (DRL) for trading orderbooks. By examining various DRL approaches, understanding their merits and drawbacks, and reviewing illustrative sample codes, readers now possess a solid foundation upon which to build sophisticated trading algorithms capable of thriving amidst volatile financial markets.
As elucidated throughout the discourse, mastering deep reinforcement learning entails grappling with fundamental tenets like value estimation, policy optimization, and exploration versus exploitation dilemmas. Moreover, proficient practitioners must be adept at selecting appropriate techniques from an array of established DRL methods, including Q-learning, actor-critic models, and policy gradient algorithms. Such expertise enables them to tackle diverse problems and attain desired outcomes.
Integral to realizing success in blending DRL algorithms with trading orderbooks is devising sound integration strategies. Savvy developers recognize potential hurdles and employ judicious case study analyses to circumvent obstacles en route to constructing resilient, high-performing trading bots. Furthermore, adherence to best practices—such as diligent hyperparameter tuning, fostering model interpretability, and ensuring reproducibility—enhances overall system robustness and credibility.
At the cutting edge of DRL application in finance, researchers continue unearthing novel ways to leverage its unique attributes for uncovering hidden patterns and gleaning lucrative insights. As advances materialize, so too do fresh opportunities for enterprising traders keen on capitalizing on burgeoning trends and expanding their arsenal of quantitative tools.
Ultimately, embracing deep reinforcement learning heralds a paradigm shift in algorithmic trading. Harnessing its potency empowers decision-makers to transcend traditional constraints, crafting ingenious solutions poised to revolutionize age-old investment precepts and captivate legions of devoted acolytes along the way.
Deep reinforcement learning for trading orderbook sample code has emerged as a vital component in modern finance, arming quants and traders alike with unprecedented abilities to analyze vast datasets, distill salient features, and execute optimal trades in near-real time. With steadfast determination and insatiable curiosity, there remains no limit to what can be achieved through the transformative powers of deep reinforcement learning.