Unleashing the Power of Machine Learning in Algorithmic Trading
The fusion of machine learning (ML) algorithms with trading bots has transformed the world of algorithmic trading, empowering automated decision-making processes and enhancing profitability. Utilizing “code samples to use in your Machine Learning trading bots “streamlines the development cycle, allowing traders to build robust and accurate trading systems efficiently. Leveraging these pre-built modules reduces complexity, saves time, and increases overall system precision.

Click Image to Find Quantum Products

Essential Components of ML Trading Bots: A High-Level Overview
Constructing successful ML trading bots involves several critical elements, each playing an integral role in ensuring optimal performance and accuracy. These fundamental components encompass:
- Data preprocessing: This stage entails cleaning raw financial data by handling inconsistencies, removing outliers, and dealing with missing information. Appropriately prepared data is vital for crafting dependable ML models.
- Feature engineering: Transforming original input variables into meaningful features can significantly improve ML model predictive capabilities. Feature scaling, extraction, and transformation are common techniques employed during this phase.
- Model selection: Selecting suitable ML algorithms tailored to specific tasks forms the cornerstone of any effective trading strategy. Commonly utilized ML models in algorithmic trading comprise linear regression, support vector machines, random forests, and neural networks.
- Backtesting: Assessing ML trading strategies’ viability requires thorough historical dataset evaluations under various market scenarios. Rigorous backtesting enables developers to fine-tune parameters, optimize entry/exit rules, and validate assumptions before actual deployment.
- Live trading: Once satisfactory results have been achieved through extensive backtesting, implementing the devised ML trading bot within real-world markets becomes feasible. Regular updates, maintenance, and monitoring ensure consistent alignment with evolving market dynamics.
By meticulously integrating these core components, aspiring developers lay a solid foundation for constructing proficient ML trading bots while capitalizing on the benefits offered by “code samples to use in your Machine Learning trading bots “to streamline the process further.

Unlocking the Potential: Exploring Sample Codes for ML Trading Bots
Capitalizing on readily available “code samples to use in your Machine Learning trading bots “offers numerous advantages throughout the development lifecycle, ultimately leading to more efficient, precise, and productive outcomes. Some key merits associated with leveraging sample codes include:
- Time efficiency: Utilizing existing code snippets allows developers to expedite project completion timelines substantially, particularly when tackling intricate ML algorithms or sophisticated trading logic implementations.
- Reduced complexity: By relying on proven solutions demonstrated via sample codes, novice programmers can circumvent obstacles related to understanding complex programming structures, thereby fostering clarity and simplicity in their creations.
- Enhanced accuracy: Adopting well-tested and vetted sample codes reduces the likelihood of introducing errors or bugs into one’s own projects, consequently increasing overall precision and reliability.
To maximally harness the power of “code samples to use in your Machine Learning trading bots “, it’s imperative to judiciously select reputable sources offering accurate, up-to-date, and diverse examples catering to varying needs and expertise levels. Furthermore, treating obtained sample codes as starting points rather than final products encourages customization, adaptation, and refinement aligned with unique project requirements.

“
How to Implement Python Libraries for Building ML Trading Bots?
Integral to the creation of Machine Learning trading bots are Python libraries, which streamline tasks and enhance functionalities throughout the development process. This section introduces several popular Python libraries instrumental in constructing ML trading bots:
NumPy
NumPy is an open-source library primarily employed for numerical computations within Python. It offers support for large, multi-dimensional arrays and matrices, along with functions for performing mathematical operations on these elements. Utilizing NumPy enables developers to execute complex calculations efficiently, thereby accelerating the overall performance of their ML trading bots.
Pandas
Complementary to NumPy, Pandas provides data manipulation capabilities tailored towards tabular data structures, including Series objects and DataFrame data structures. With features enabling easy handling of missing or duplicate data points, merging datasets, and applying customized transformations, Pandas simplifies data preprocessing—a critical step in crafting robust ML models.
Scikit-learn
As one of the most widely adopted ML libraries globally, Scikit-learn encompasses various tools necessary for implementing ML algorithms effectively. Among its offerings are numerous prefabricated classifiers, regressors, clustering modules, dimensionality reduction techniques, and cross-validation utilities. Leveraging Scikit-learn’s extensive suite of resources facilitates seamless transition from dataset exploration to predictive model generation.
TensorFlow & Keras
Specifically designed for deep learning applications, TensorFlow serves as a powerful platform capable of managing computation graphs across diverse devices and architectures. Built atop TensorFlow, Keras is a user-friendly neural network API offering rapid prototyping through modular construction blocks called layers. Together, they empower developers to design sophisticated ML models incorporating artificial neural networks (ANNs), convolutional neural networks (CNNs), recurrent neural networks (RNNs), and other advanced architectural designs.
Backtrader
Dedicated explicitly to algorithmic trading endeavors, Backtrader is an open-source framework furnishing users with backtesting and paper trading capacities. By integrating strategy logic, broker emulators, and technical indicators into a single cohesive unit, Backtrader expedites the development lifecycle while ensuring compatibility among disparate components. Consequently, it has become indispensable for practitioners seeking to evaluate and refine ML trading bot strategies before engaging in live markets.
To demonstrate fundamental usage and functionality provided by each library, consult the following sample codes:
# Import NumPy library import numpy as np # Generate random array arr = np.random.rand(5, 3) print("Array:\n", arr) # Perform matrix multiplication matmul_result = np.dot(arr, arr) print("\nMatrix Multiplication Result:\n", matmul_result)# Import Pandas library import pandas as pd # Create simple DataFrame data = {'A': [1, 2, 3], 'B': [4, 5, 6]} df = pd.DataFrame(data) print("DataFrame:\n", df) # Drop null values clean_df = df.dropna() print("\nClean DataFrame:\n", clean_df)# Import Scikit-learn library from sklearn import datasets from sklearn.model_selection import train_test_split # Load iris dataset iris = datasets.load_iris() X = iris['data'] y = iris['target'] # Split dataset into training and testing subsets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Train linear SVC classifier from sklearn.svm import LinearSVC clf = LinearSVC().fit(X_train, y_train) # Evaluate model performance accuracy = clf.score(X_test, y_test) print("Accuracy:", accuracy)# Import TensorFlow and Keras libraries import tensorflow as tf from tensorflow import keras # Define sequential model architecture model = keras.Sequential([ keras.layers.Flatten(input_shape=(28, 28)), keras.layers.Dense(128, activation='relu'), keras.layers.Dropout(0.2), keras.layers.Dense(10, activation='softmax') ]) # Compile model model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # Train model on MNIST dataset mnist = keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() model.fit(x_train, y_train, epochs=5) # Evaluate model performance loss, accuracy = model.evaluate(x_test, y_test) print("Loss:", loss) print("Accuracy:", accuracy)# Import Backtrader library import backtrader as bt # Create cerebro instance cerebro = bt.Cerebro() # Define strategy logic class MyStrategy(bt.Strategy): def __init__(self): pass def next(self): pass # Add strategy to cerebro cerebro.addstrategy(MyStrategy) # Set initial capital cerebro.broker.setcash(100000.0) # Run simulation cerebro.run()
”
Data Preparation Techniques for Crafting Robust ML Models
When it comes to leveraging code samples to excel in machine learning (ML) trading bot development, understanding the importance of data preparation is paramount. Financial datasets possess unique characteristics requiring specific treatment before being fed into ML models. This section details four crucial steps involved in preparing these datasets: handling missing values, detecting anomalies, normalizing features, and applying resampling techniques.
Imputing Missing Values
Missing data points are common in financial time series due to various reasons such as delayed reporting or erratic information dissemination. Imputing these missing values becomes necessary since most ML algorithms cannot handle them directly. Common strategies include forward fill, backward fill, mean/median/mode imputation, and advanced interpolation methods. It’s vital to assess each strategy’s suitability depending on the dataset and problem at hand.
Anomaly Detection
Financial markets often experience extreme events leading to outliers or anomalous observations within datasets. These aberrations can significantly affect ML model performance if left untreated. Anomaly detection techniques help identify and manage such instances by employing statistical measures, density estimation, clustering, or neural network-based approaches. By incorporating robust anomaly detection mechanisms, developers ensure that ML trading bots make informed decisions based on cleaner and more reliable data.
Feature Normalization
Many ML algorithms assume input variables follow similar scales to converge efficiently during training. However, financial features may exhibit varying magnitudes, rendering direct application of certain ML algorithms suboptimal. Feature scaling techniques like min-max normalization, z-score standardization, or robust scaling address this challenge by transforming raw inputs into comparable units. Consequently, normalized features enable better generalization across different asset classes and improve overall ML model performance.
Resampling Techniques
Intraday high-frequency trading generates large volumes of data necessitating judicious sampling strategies for effective ML model construction. Resampling techniques like uniform random sampling, systematic sampling, or cluster-based sampling offer viable solutions to reduce dataset size while preserving critical temporal dependencies. Moreover, frequency domain conversion through wavelet decomposition enables multi-resolution analysis, allowing simultaneous exploration of short-term patterns and long-term trends embedded within financial time series. By meticulously following these data preparation techniques, developers lay solid foundations for constructing accurate and dependable ML trading bots. Utilizing relevant code samples streamlines this process further, ensuring timely completion and minimizing potential errors associated with manual implementation. Ultimately, well-prepared datasets form the cornerstone of successful ML trading bot projects, harnessing the power of code samples to enhance decision-making capabilities and drive automated trading strategies.
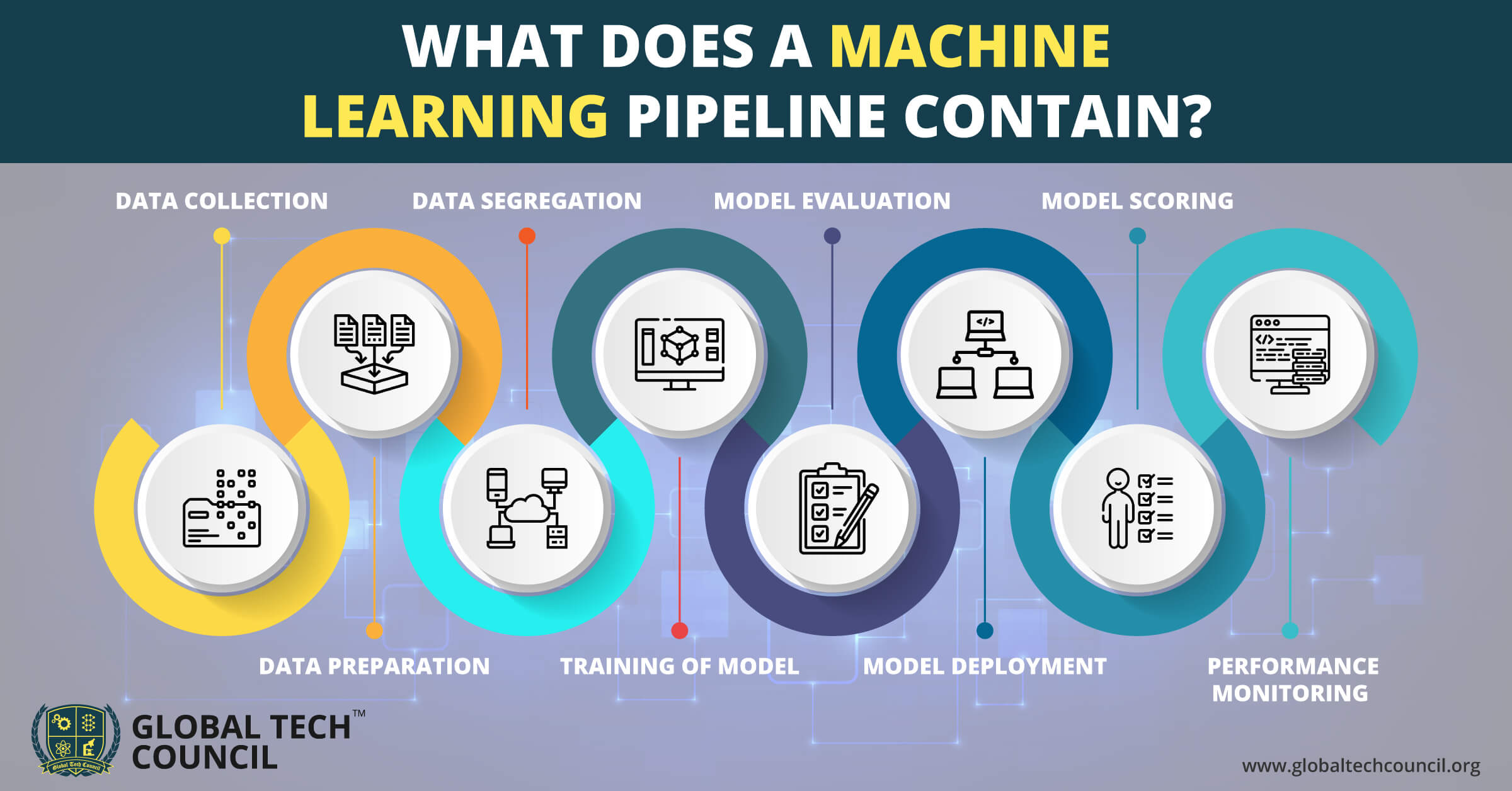
Selecting Suitable ML Algorithms for Various Market Conditions
As part of an overarching approach towards crafting proficient ML trading bots, choosing fitting ML algorithms tailored to diverse market scenarios plays a pivotal role in determining success. Delving deeper into this subject matter entails examining both supervised and unsupervised learning methodologies alongside pertinent issues related to regression versus classification challenges and ensemble approaches.
Supervised vs Unsupervised Learning Methods
At its core, supervised learning involves gleaning insights from labeled data, where target outcomes are discernible. For instance, predicting future stock prices given historical price trajectories exemplifies a supervised learning task. Popular ML algorithms encompass linear regression, logistic regression, support vector machines (SVM), k-nearest neighbors (KNN), and naive Bayes classifiers.
Conversely, unsupervised learning grapples with unlabeled data, focusing primarily on discovering underlying structures devoid of explicit outcome knowledge. Cluster analysis and dimensionality reduction typify unsupervised learning applications, including k-means clustering, hierarchical agglomerative clustering (HAC), principal component analysis (PCA), and t-distributed stochastic neighbor embedding (t-SNE).
Regression vs Classification Problems
Distinguishing between regression and classification problems constitutes another fundamental aspect of algorithm selection. Regression tasks aim to forecast numerical outputs – e.g., estimating Bitcoin’s closing price after three days – whereas classification objectives revolve around categorizing discrete labels – e.g., distinguishing bullish from bearish market phases. Accordingly, adopting suitable evaluation matrices ensures optimal performance assessment; mean squared error (MSE) or root mean squared error (RMSE) serve as preferred choices for regression exercises, while accuracy, precision, recall, F1 score, or area under the receiver operating characteristic curve (AUC-ROC) reign supreme in classification settings.
Ensemble Approaches
Lastly, integrating multiple base learners via ensemble approaches frequently bolsters overall prediction accuracy compared to relying solely on individual models. Ensemble techniques generally fall under two categories: bagging (bootstrap aggregating) and boosting. Bagging reduces variance by averaging predictions derived from numerous randomly sampled datasets, thereby mitigating overfitting concerns. Random forests epitomize bagging implementations, amalgamating myriad decision trees trained independently on distinct subsamples drawn with replacement from the original dataset.
Alternatively, boosting dynamically adjusts subsequent learner weights contingent upon preceding iterations’ performance, progressively refining cumulative predictions until satisfactory results emerge. Gradient tree boosting (GTB) represents a widely employed boosting paradigm, sequentially combining weak learners – typically shallow decision trees – to generate increasingly potent meta-estimators capable of capturing intricate pattern nuances inherent in complex financial systems.
In conclusion, astute algorithm selection forms a critical pillar supporting robust ML trading bot development. Leveraging code samples facilitates efficient experimentation across disparate learning methodologies, enabling practitioners to pinpoint ideal candidates suited for varied market circumstances. Armed with this arsenal of tools and techniques, aspiring traders stand poised to capitalize on burgeoning opportunities presented by dynamic global financial networks.
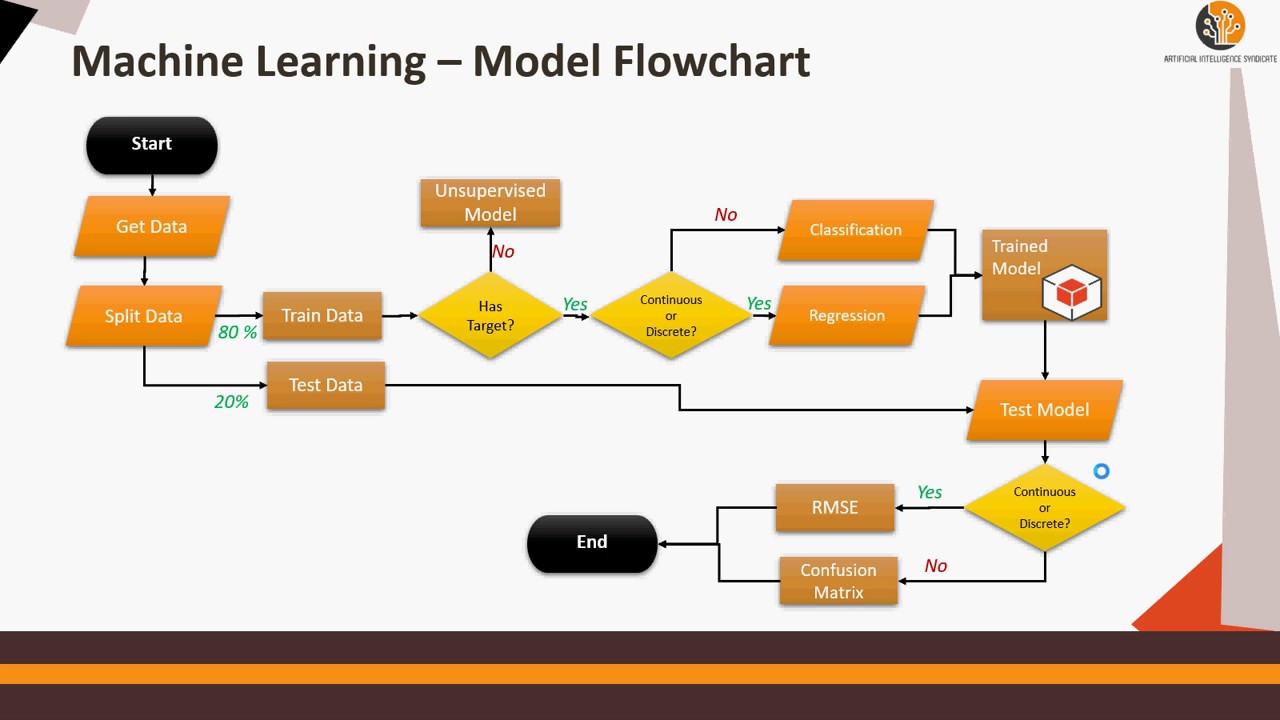
Backtesting Strategies: Validating Performance Before Live Deployment
An indispensable facet of constructing effective ML trading bots hinges on meticulous backtesting protocols designed to evaluate prospective strategies before actual implementation. By simulating past market dynamics, developers can ascertain feasibility, gauge profitability, and identify potential pitfalls, ultimately fostering well-informed decisions regarding deployment. This section elucidates several best practices integral to thorough backtesting procedures, namely walkforward optimization, Monte Carlo simulations, and transaction cost modeling.
Walkforward Optimization
Walkforward optimization embodies a systematic technique for assessing model efficacy through recursive training and testing cycles. Initiating with an initial training phase, the model is subsequently tested on out-of-sample data spanning a designated interval. Post-evaluation, the training window advances incrementally, incorporating newly available information while concurrently shifting the test set forward. Reiterating these consecutive stages culminates in a series of overlapping trials encapsulating various temporal segments, thus providing a more holistic perspective on model adaptability and generalizability.
Monte Carlo Simulations
Complementary to walkforward optimization, Monte Carlo simulations offer an alternative avenue for stress-testing ML trading bots under diverse hypothetical scenarios. Through generating randomized inputs reflective of real-world market fluctuations, developers procure valuable insights concerning strategy resilience amidst volatile environments. Moreover, this probabilistic framework enables quantification of risk exposure, facilitating informed judgments vis-à-vis acceptable levels of uncertainty and desired return thresholds.
Transaction Cost Modeling
Integral to any realistic appraisal of ML trading bot performance involves accounting for transaction costs associated with executing trades. These expenses manifest in manifold guises, inclusive of brokerage fees, bid-ask spread differentials, slippage effects, and tax implications. Consequently, neglecting these factors may yield misleading projections skewed favorably, leading to illusory expectations once confronted with practical constraints. Therefore, diligent developers incorporate transaction cost modeling within backtesting routines, ensuring accurate representation of net returns commensurate with industry standards.
In summary, rigorous backtesting procedures represent a cornerstone of successful ML trading bot construction, affording developers the opportunity to scrutinize candidate strategies under controlled conditions prior to engaging tangible assets. Adherence to recommended practices, such as walkforward optimization, Monte Carlo simulations, and transaction cost modeling, fortifies confidence in model aptitude whilst simultaneously minimizing risks inherent in live trading scenarios. As such, embracing these tenets engenders heightened preparedness and equips practitioners with requisite skills necessary to navigate the evolving landscape of algorithmic finance confidently.
Monitoring and Updating ML Trading Bot Models for Continuous Improvement
A critical aspect of devising proficient ML trading bots entails implementing robust mechanisms for ongoing surveillance and periodic updates. Such measures ensure sustained relevance and effectiveness by adapting to emergent trends, mitigating obsolescence, and capitalizing upon discernible patterns within ever-evolving market landscapes. This segment delineates key elements instrumental in achieving consistent improvement, encompassing retraining schedules, performance tracking metrics, and seamless integration workflows.
Establishing Retraining Schedules
Instituting recurring retraining intervals represents a pivotal component of maintaining up-to-date ML trading bot models. Periodically reintroducing fresh data coalesced with refined features not only bolsters predictive capabilities but also circumvents stagnant performance attributable to static configurations. Developers must judiciously balance frequency against computational overhead, striking an optimal equilibrium tailored to specific application requirements.
Implementing Performance Tracking Metrics
Effective assessment of ML trading bot prowess necessitates employment of discriminating evaluation criteria capable of capturing nuanced distinctions across disparate methodologies. Utilizing granular metrics germane to both business objectives and domain expertise ensures incisive feedback imperative for honing precision, augmenting recall, and optimizing overall efficiency. Examples comprise accuracy scores, F1 ratings, area under curve (AUC) measurements, drawdown percentages, and Sharpe ratios among others.
Facilitating Continuous Integration Workflows
Orchestrating streamlined update processes demands establishment of automated pipelines integrating version control systems, issue ticketing platforms, and cloud computing services. Automated testing suites further enhance reliability via exhaustive validation checks conducted throughout each stage of the development lifecycle. Ultimately, these integrated workflows foster efficient collaboration amongst cross-functional teams whilst expediting iterative improvements aligned with burgeoning user needs and dynamic market forces.
In conclusion, dedicated attention towards monitoring and updating deployed ML trading bot models significantly enhances longevity and potency within competitive markets. By instituting retraining schedules, leveraging cogent performance tracking metrics, and cultivating harmonious continuous integration workflows, developers consistently elevate system acumen whilst reducing susceptibility to erratic fluctuations endemic in financial ecosystems. Thus, astute practitioners recognize the salient importance of perpetual enhancement, thereby solidifying their strategic advantage within the realm of algorithmic finance.
