The Intersection of Machine Learning and Trading
Machine learning, a subset of artificial intelligence, has been increasingly adopted in various industries, including finance and trading. The best machine learning strategies for trading involve leveraging these advanced algorithms to identify patterns, predict market trends, and optimize decision-making processes. By integrating machine learning techniques, traders and investors can potentially enhance their accuracy, efficiency, and risk management.

Click Image to Find Quantum Products

Machine Learning vs. Traditional Trading: A Comparative Analysis
Machine learning-based trading strategies and traditional trading methods differ in several aspects, including adaptability, efficiency, and risk management. By understanding these differences, traders and investors can make informed decisions about incorporating machine learning techniques into their trading strategies.
- Adaptability: Traditional trading strategies rely on predefined rules and static models, making them less flexible in adapting to changing market conditions. In contrast, machine learning models can learn from new data and adapt to market shifts, providing more dynamic and responsive trading strategies.
- Efficiency: Machine learning models can process vast amounts of data more efficiently than traditional trading methods. By analyzing historical and real-time data, machine learning algorithms can identify patterns and predict market trends more accurately, ultimately leading to more informed trading decisions.
- Risk Management: Machine learning models can help traders manage risk more effectively by predicting potential losses and identifying opportunities for risk mitigation. Through advanced algorithms and predictive analytics, machine learning strategies can optimize risk-reward ratios and improve overall trading performance.

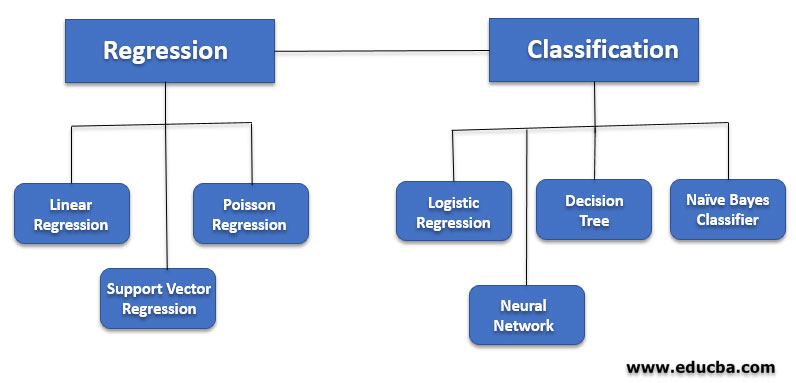
1. Supervised Learning: Regression and Classification Techniques
Supervised learning is a popular machine learning approach in trading, utilizing labeled data to train models that predict future outcomes based on past performance. Regression and classification techniques are two primary supervised learning methods with practical applications in trading.
Regression Techniques
Regression techniques are used to predict continuous outcomes, making them suitable for forecasting asset prices, volatility, or returns. Common regression techniques in trading include:
- Linear Regression: A simple yet powerful technique that models the relationship between a dependent variable and one or more independent variables using a linear function. Linear regression can be applied to trading strategies to predict future price movements based on historical data.
- Polynomial Regression: An extension of linear regression that allows for modeling nonlinear relationships between variables. Polynomial regression can capture complex patterns in trading data, improving prediction accuracy.
- Ridge Regression and Lasso Regression: Regularization techniques that prevent overfitting by adding a penalty term to the loss function. These methods are particularly useful when dealing with a large number of input variables or features.
Classification Techniques
Classification techniques are used to predict categorical outcomes, such as whether a stock will go up or down. Common classification techniques in trading include:
- Logistic Regression: A statistical method that models the probability of a binary outcome (e.g., 1 or 0, up or down) using a logistic function. Logistic regression can be applied to trading strategies to predict the likelihood of price movements based on historical data.
- Decision Trees: A hierarchical model that recursively splits the data into subsets based on feature values. Decision trees can be used to create trading rules by identifying patterns and relationships in the data.
- Random Forests: An ensemble method that combines multiple decision trees to improve prediction accuracy. Random forests reduce overfitting and increase robustness compared to individual decision trees.
While supervised learning techniques can significantly enhance trading strategies, they are not without limitations. Overfitting, lookahead bias, and data snooping are common challenges that must be addressed to ensure the effectiveness and reliability of machine learning models in trading.
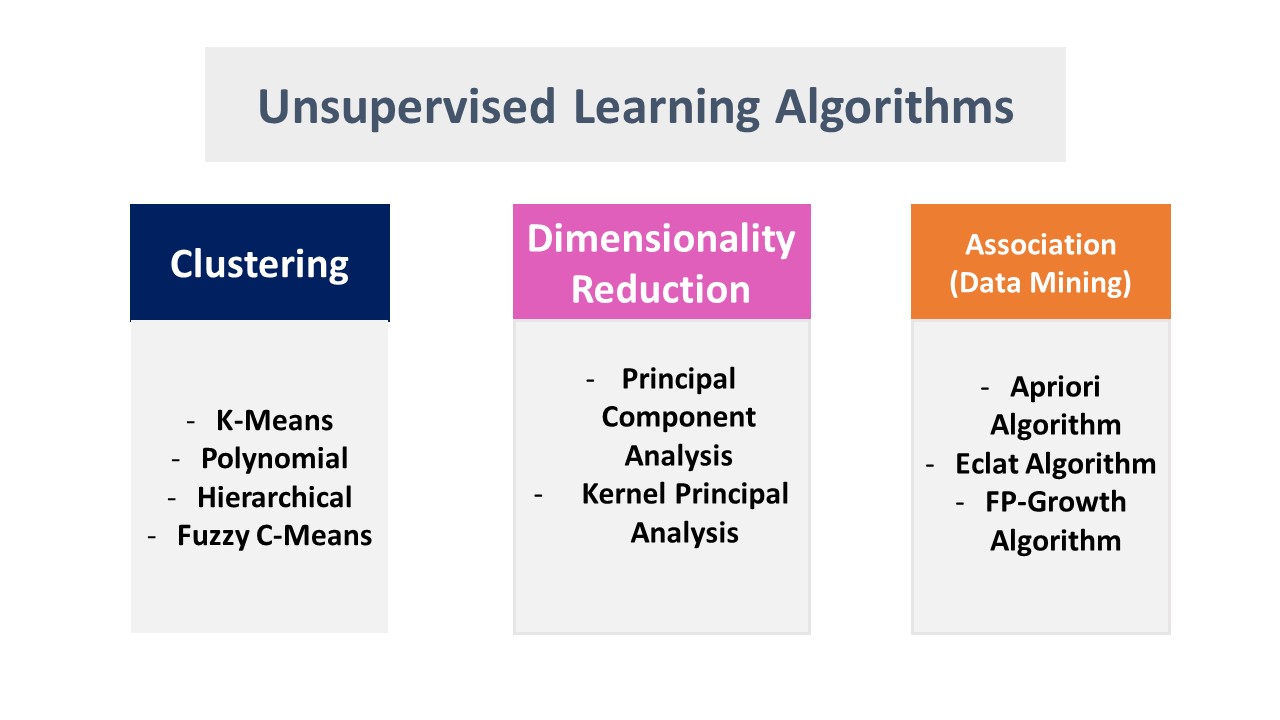
2. Unsupervised Learning: Clustering and Dimensionality Reduction
Unsupervised learning strategies are valuable for trading, enabling the discovery of hidden patterns and structures within data without explicit labels. Clustering and dimensionality reduction techniques are two primary unsupervised learning methods with practical applications in trading.
Clustering Techniques
Clustering techniques group similar data points together, revealing underlying patterns and relationships. Common clustering techniques in trading include:
- K-means Clustering: A simple yet effective technique that partitions data into K clusters based on feature similarity. K-means clustering can be used to identify groups of stocks with similar price movements or volatility patterns.
- Hierarchical Clustering: A hierarchical method that creates a tree-like structure of clusters, where each node represents a cluster of data points. Hierarchical clustering can be used to visualize the relationships between clusters and identify nested structures in trading data.
- DBSCAN: A density-based clustering algorithm that groups data points based on local density. DBSCAN can identify clusters of arbitrary shape and is robust to noise, making it suitable for trading scenarios with complex data structures.
Dimensionality Reduction Techniques
Dimensionality reduction techniques aim to reduce the number of input variables or features while preserving the essential information. Common dimensionality reduction techniques in trading include:
- Principal Component Analysis (PCA): A linear dimensionality reduction method that projects high-dimensional data onto a lower-dimensional space while preserving the maximum variance. PCA can be used to identify the most important factors driving trading returns or volatility.
- t-distributed Stochastic Neighbor Embedding (t-SNE): A nonlinear dimensionality reduction method that preserves local structure and is particularly useful for visualizing high-dimensional data. t-SNE can be used to identify patterns and relationships in trading data that may not be apparent in the original feature space.
Unsupervised learning techniques offer several advantages for trading, including the ability to discover hidden patterns, identify data structures, and reduce dimensionality. However, they also present challenges, such as the need to determine the optimal number of clusters or components and the potential for overfitting. Careful consideration of these factors and adherence to best practices can help ensure the effectiveness and reliability of unsupervised learning models in trading.
3. Reinforcement Learning: Optimal Decision Making in Trading
Reinforcement learning (RL) is a type of machine learning strategy that focuses on optimal decision making in trading scenarios. RL algorithms learn by interacting with an environment and receiving feedback in the form of rewards or penalties. By continuously adjusting their actions based on this feedback, RL agents can learn to make increasingly informed and profitable decisions.
Key Reinforcement Learning Algorithms
Several RL algorithms are particularly relevant to trading, including:
- Q-learning: A value-based RL algorithm that learns the optimal action-value function, which estimates the expected cumulative reward for taking a specific action in a given state. Q-learning can be used to develop trading strategies that balance risk and reward, such as optimal entry and exit points for trades.
- Policy Gradients: A policy-based RL algorithm that directly optimizes the policy function, which maps states to actions. Policy gradients can be used to learn complex trading strategies that involve multiple assets or decision variables, such as portfolio optimization and dynamic asset allocation.
Advantages of Reinforcement Learning in Trading
Reinforcement learning offers several advantages for trading, including:
- Adaptability: RL algorithms can continuously learn and adapt to changing market conditions, making them well-suited for dynamic trading environments.
- Scalability: RL algorithms can be applied to a wide range of trading scenarios, from individual stocks to complex portfolios.
- Generalization: RL algorithms can learn from experience and apply that knowledge to new, unseen trading scenarios, improving their ability to make informed decisions in novel situations.
However, reinforcement learning also presents challenges, such as the need for extensive training data, the potential for overfitting, and the difficulty of defining appropriate reward functions. Careful consideration of these factors and adherence to best practices can help ensure the effectiveness and reliability of reinforcement learning models in trading.
How to Incorporate Machine Learning Strategies in Trading
Implementing machine learning strategies in trading can be a complex process, but by following a systematic approach, traders can increase their chances of success. Here is a step-by-step guide on how to incorporate best machine learning strategies for trading:
Step 1: Data Collection
The first step in implementing machine learning strategies in trading is to collect high-quality, relevant data. This data can include historical price and volume data, fundamental data, and alternative data sources. Ensuring that the data is clean, accurate, and representative of the trading scenario is crucial for the success of the machine learning model.
Step 2: Data Preprocessing
Once the data has been collected, it must be preprocessed to prepare it for use in the machine learning model. This can include cleaning the data, normalizing it, and transforming it into a format that is suitable for the machine learning algorithm. Data preprocessing is an essential step in the machine learning process, as it can significantly impact the accuracy and reliability of the model.
Step 3: Model Selection
Choosing the right machine learning model is critical for the success of the trading strategy. There are a variety of machine learning algorithms to choose from, including supervised learning, unsupervised learning, and reinforcement learning models. Each algorithm has its strengths and weaknesses, and selecting the one that is best suited for the trading scenario is essential.
Step 4: Training and Validation
Once the model has been selected, it must be trained on a portion of the data and validated on another portion. This process helps to ensure that the model is accurate and reliable, and that it can generalize well to new, unseen data. During the training and validation process, it is essential to monitor the model’s performance and adjust its parameters as necessary to optimize its accuracy.
Step 5: Evaluation
After the model has been trained and validated, it must be evaluated on a separate test set to ensure that it is robust and reliable. This evaluation process can include a variety of metrics, such as accuracy, precision, recall, and F1 score. By evaluating the model on a separate test set, traders can ensure that the model is not overfitting to the training data and that it can generalize well to new data.
By following these steps, traders can incorporate best machine learning strategies for trading into their trading strategies, increasing their accuracy and efficiency. However, it is essential to remember that machine learning is not a silver bullet, and that careful consideration of the challenges and limitations of machine learning in trading is necessary to ensure the success of the trading strategy.

Challenges and Limitations of Machine Learning in Trading
While machine learning has the potential to revolutionize trading, it is not without its challenges and limitations. Here are some of the most significant issues that traders should be aware of when implementing machine learning strategies:
Overfitting
Overfitting occurs when a machine learning model is trained too closely to the training data, resulting in poor performance on new, unseen data. To avoid overfitting, traders must use techniques such as cross-validation, regularization, and early stopping. Additionally, it is essential to ensure that the model is not too complex and that the data is representative of the trading scenario.
Lookahead Bias
Lookahead bias occurs when a machine learning model is trained on data that includes future information that would not be available in a real-world trading scenario. To avoid lookahead bias, traders must ensure that the data is clean, accurate, and free from future information. Additionally, it is essential to evaluate the model on a separate test set to ensure that it can generalize well to new, unseen data.
Data Snooping
Data snooping occurs when a trader tests a large number of machine learning models on the same data set, resulting in a higher likelihood of finding a model that performs well by chance. To avoid data snooping, traders must use techniques such as cross-validation, regularization, and early stopping. Additionally, it is essential to ensure that the data is representative of the trading scenario and that the model is not too complex.
Potential Solutions and Best Practices
To mitigate these issues, traders can follow best practices such as:
- Using high-quality, relevant data that is free from future information
- Preprocessing the data to ensure that it is clean, accurate, and representative of the trading scenario
- Selecting the right machine learning model for the trading scenario
- Monitoring the model’s performance during the training and validation process
- Evaluating the model on a separate test set to ensure that it is robust and reliable
- Adhering to industry standards and guidelines regarding ethical considerations and regulations
By following these best practices, traders can mitigate the challenges and limitations of machine learning in trading and increase their chances of success. However, it is essential to remember that machine learning is not a silver bullet, and that careful consideration of the potential issues is necessary to ensure the success of the trading strategy.

Ethical Considerations and Regulations in Machine Learning Trading
As machine learning becomes increasingly prevalent in trading, it is essential to consider the ethical implications and regulatory frameworks that govern its use. Here are some of the most significant ethical considerations and regulations that traders should be aware of when implementing machine learning strategies:
Data Privacy
Machine learning models rely on large amounts of data to make accurate predictions. However, the use of this data raises concerns about data privacy and security. Traders must ensure that they comply with data protection regulations, such as the General Data Protection Regulation (GDPR) in the European Union, and that they obtain informed consent from data subjects before using their data. Additionally, traders must ensure that the data is anonymized and encrypted to prevent unauthorized access.
Market Manipulation
Machine learning models can potentially be used to manipulate the market, for example, by creating fake orders to move the price in a particular direction. Traders must ensure that they comply with market manipulation regulations, such as the Market Abuse Regulation (MAR) in the European Union, and that they do not engage in any behavior that could be perceived as manipulative. Additionally, traders must ensure that their machine learning models are transparent and auditable to prevent any suspicion of market manipulation.
Transparency
Machine learning models can be complex and difficult to interpret, making it challenging to understand how they make decisions. Traders must ensure that their machine learning models are transparent and explainable to regulators, investors, and other stakeholders. Additionally, traders must ensure that they can provide clear and concise explanations of how their machine learning models work and how they make decisions. This transparency is essential to maintain trust and confidence in the trading strategy.
Adhering to Industry Standards and Guidelines
Traders must adhere to industry standards and guidelines regarding the use of machine learning in trading. For example, the Financial Conduct Authority (FCA) in the United Kingdom has published guidelines on the use of artificial intelligence and machine learning in financial services. These guidelines provide best practices for implementing machine learning models in trading, including data management, model validation, and risk management. Adhering to these guidelines can help traders ensure that they are using machine learning in a responsible and ethical manner.
By considering these ethical considerations and regulations, traders can ensure that they are using machine learning in a responsible and ethical manner. Additionally, by adhering to industry standards and guidelines, traders can maintain trust and confidence in their trading strategies and avoid any potential regulatory issues. Ultimately, the use of machine learning in trading is a powerful tool, but it must be used responsibly and ethically to ensure its long-term success.