Deep Reinforcement Learning: A Powerful Tool for Stock Momentum Trading
Deep reinforcement learning (DRL) is a cutting-edge machine learning technique that combines the power of deep neural networks with reinforcement learning principles. This innovative approach enables AI agents to learn from data, adapt to dynamic environments, and make informed decisions based on experience. In the context of stock momentum trading, DRL offers a unique set of advantages that can significantly enhance trading strategies.

Click Image to Find Quantum Products
By applying DRL to stock momentum trading, investors can leverage the ability of AI models to learn from historical data, identify patterns, and predict future price movements. The primary goal is to create a system that can make profitable trades, minimize risks, and maximize long-term returns. The use of DRL in stock momentum trading is a promising avenue, as it allows for the development of sophisticated strategies that can adapt to changing market conditions and continuously improve over time.
The integration of DRL in stock momentum trading is an exciting development in the field of AI-driven finance. By harnessing the potential of DRL, investors can gain a competitive edge and unlock new opportunities for growth and success. In the following sections, we will explore the various aspects of implementing DRL for stock momentum trading, including data set selection, reward function design, algorithm choice, and model evaluation.
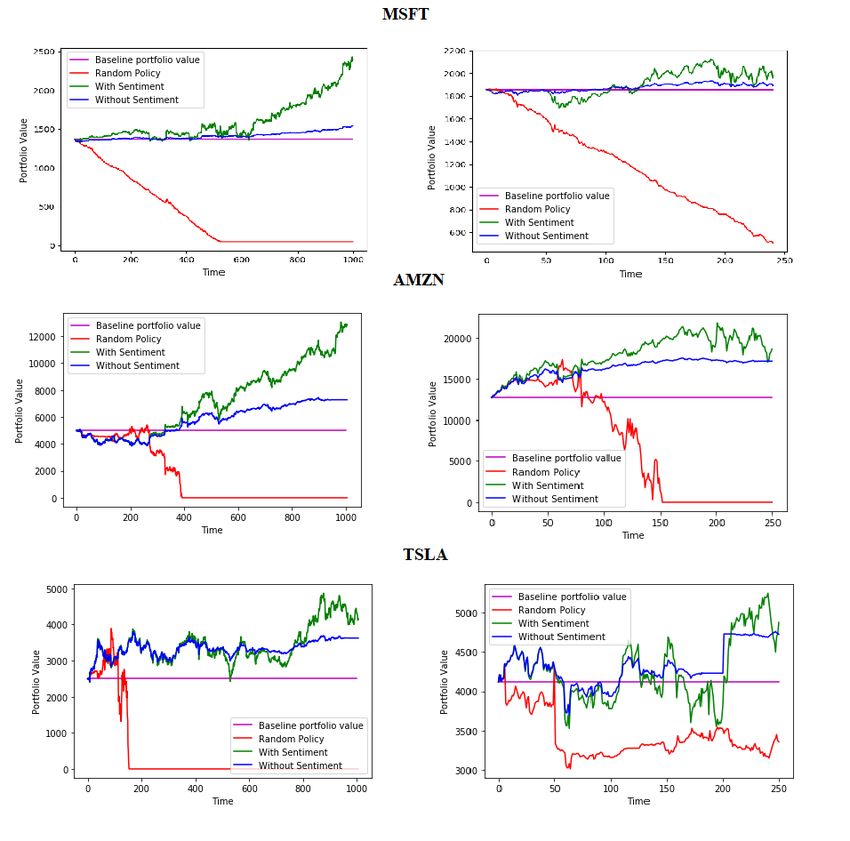
Identifying Suitable Data Sets for Training Deep Reinforcement Learning Models
Selecting appropriate data sets is crucial for training effective deep reinforcement learning (DRL) models in stock momentum trading. High-quality data sets enable DRL models to learn from historical market patterns, identify profitable trading opportunities, and adapt to changing market conditions. In this section, we will discuss the role of historical stock prices, trading volumes, and other market indicators in creating a robust training data set.
A suitable data set for stock momentum trading typically includes historical stock prices, trading volumes, and various technical and fundamental indicators. These data sets can be obtained from financial data providers, such as Yahoo Finance, Quandl, or Alpha Vantage. When constructing a data set, it is essential to consider factors such as data frequency (daily, hourly, or minute-level), time frame (e.g., 1 year, 5 years, or 10 years), and geographical coverage (global or regional markets).
Data preprocessing, cleaning, and normalization are critical steps in preparing a data set for DRL model training. Preprocessing involves handling missing or erroneous data points, while cleaning involves removing outliers or irrelevant data. Normalization is the process of scaling numerical data to a common range, which helps improve model convergence and performance. Common normalization techniques include min-max scaling and z-score normalization.
When creating a data set for stock momentum trading, it is essential to consider the following tips:
- Ensure data integrity and consistency by checking for errors, missing values, and outliers.
- Preprocess data by handling missing values, removing irrelevant features, and scaling numerical data.
- Include a diverse set of features, such as historical prices, trading volumes, and technical indicators, to capture various aspects of market dynamics.
- Consider the time frame and frequency of the data to capture both short-term and long-term market trends.
- Split the data into training, validation, and testing sets to evaluate model performance and avoid overfitting.
By following these best practices, investors can create high-quality data sets that enable DRL models to learn from historical market patterns and make informed trading decisions. In the following sections, we will discuss reward function design, algorithm selection, and model implementation for stock momentum trading using DRL.
Designing Effective Reward Functions for Stock Momentum Trading
Reward functions play a critical role in deep reinforcement learning (DRL) models, guiding the learning process by providing feedback on the agent’s actions. In stock momentum trading, designing effective reward functions is essential for encouraging profitable trades, minimizing risks, and promoting long-term returns. In this section, we will discuss the significance of reward functions and provide examples of potential reward functions and their trade-offs.
A well-designed reward function should strike a balance between exploration and exploitation, encouraging the agent to explore new trading strategies while also exploiting proven profitable opportunities. Reward functions can be based on various metrics, such as cumulative returns, risk-adjusted returns, or transaction costs.
Here are some examples of reward functions for stock momentum trading:
- Simple Return: This reward function is based on the difference between the current portfolio value and the previous portfolio value. While this function is easy to implement, it may not adequately consider the risks associated with each trade.
- Risk-Adjusted Return: This reward function takes into account both the returns and the risks of each trade. Common risk-adjusted return metrics include the Sharpe ratio, Sortino ratio, or Calmar ratio. By incorporating risk, this reward function encourages the agent to make more informed trading decisions.
- Transaction Costs: This reward function includes the costs associated with each trade, such as commission fees, bid-ask spreads, or slippage. By considering transaction costs, the agent is incentivized to make more cost-effective trades and avoid overtrading.
When designing reward functions for stock momentum trading, it is essential to consider the following factors:
- Ensure that the reward function aligns with the overall trading objectives, such as maximizing returns, minimizing risks, or reducing transaction costs.
- Avoid reward functions that encourage short-term speculation or risky trading behaviors, as they may lead to suboptimal performance in the long run.
- Consider the trade-offs between exploration and exploitation, as reward functions that are too conservative may limit the agent’s ability to learn from new trading opportunities.
- Regularly review and update the reward function to ensure that it remains relevant and effective as market conditions change.
By designing effective reward functions, investors can guide deep reinforcement learning models to make informed trading decisions that align with their overall investment objectives. In the following sections, we will discuss algorithm selection, implementation, and training strategies for stock momentum trading using DRL.
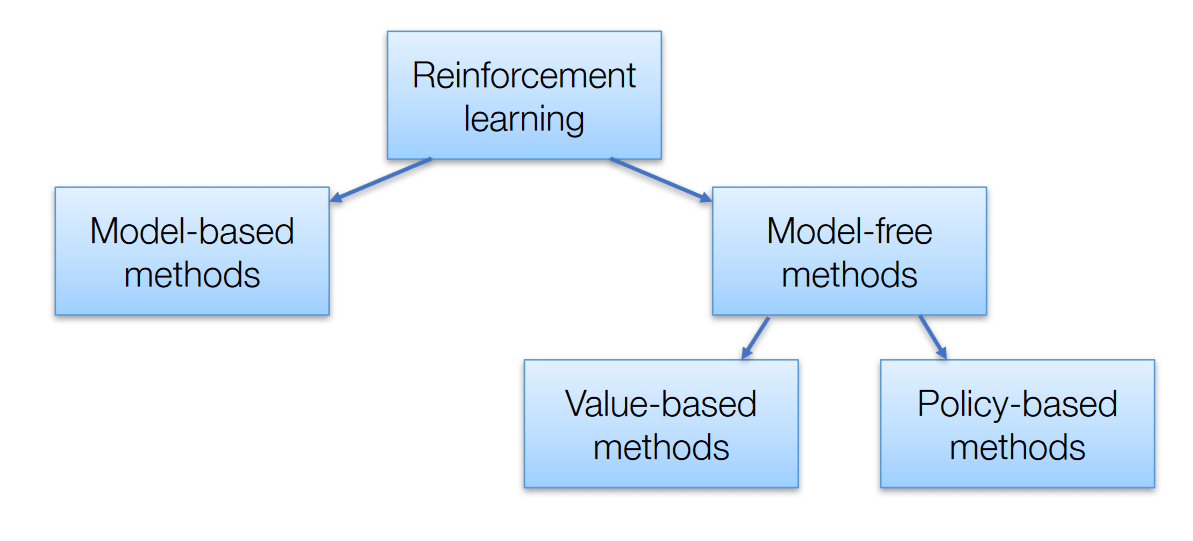
Selecting the Right Deep Reinforcement Learning Algorithms for Stock Momentum Trading
Deep reinforcement learning (DRL) algorithms offer a powerful approach to stock momentum trading, enabling models to learn from data, adapt to market changes, and make informed decisions. However, with various algorithms available, such as Deep Q-Networks (DQN), Proximal Policy Optimization (PPO), and Advantage Actor-Critic (A2C), selecting the most suitable algorithm for a given trading scenario can be challenging. In this section, we will compare the strengths, weaknesses, and computational requirements of these algorithms and provide guidance on making the right choice.
Deep Q-Networks (DQN)
DQN is a value-based DRL algorithm that combines Q-learning with a deep neural network to approximate the action-value function. DQN is well-suited for discrete action spaces, making it an ideal choice for stock momentum trading scenarios with a limited number of predefined actions, such as buy, hold, or sell.
- Strengths: DQN is relatively easy to implement and computationally efficient, as it only requires training a value function.
- Weaknesses: DQN may struggle with high-dimensional or continuous action spaces, and it can suffer from instability during training due to the correlation between consecutive samples.
- Computational Requirements: DQN has lower computational requirements compared to policy-based methods, making it more accessible for practitioners with limited resources.
Proximal Policy Optimization (PPO)
PPO is a policy-based DRL algorithm that aims to address the challenges of policy gradient methods, such as high variance and instability during training. PPO strikes a balance between sample complexity and computational efficiency, making it suitable for high-dimensional or continuous action spaces.
- Strengths: PPO is more stable during training compared to traditional policy gradient methods, and it can handle high-dimensional or continuous action spaces.
- Weaknesses: PPO may require more computational resources compared to value-based methods like DQN.
- Computational Requirements: PPO has higher computational requirements than DQN, as it involves training both a policy and a value function.
Advantage Actor-Critic (A2C)
A2C is a policy-based DRL algorithm that combines the benefits of actor-critic methods with the advantages of using a value function to reduce the variance of policy gradient estimates. A2C is well-suited for high-dimensional or continuous action spaces and can handle complex trading scenarios.
- Strengths: A2C offers lower variance and better sample efficiency compared to traditional policy gradient methods, and it can handle high-dimensional or continuous action spaces.
- Weaknesses: A2C may require more computational resources compared to value-based methods like DQN.
- Computational Requirements: A2C has higher computational requirements than DQN, as it involves training both a policy and a value function.
When selecting a DRL algorithm for stock momentum trading, consider the following factors:
- Action Space: For discrete action spaces, DQN is a suitable choice. For high-dimensional or continuous action spaces, consider policy-based methods like PPO or A2C.
- Computational Resources: Evaluate the available computational resources and select an algorithm that strikes a balance between complexity and efficiency.
- Trading Scenario: Assess the complexity of the trading scenario and choose an algorithm that can effectively handle the required action space and computational requirements.
By selecting the right DRL algorithm, investors can develop effective stock momentum trading strategies that leverage the power of AI and machine learning to learn from data, adapt to market changes, and make informed decisions.
Implementing Deep Reinforcement Learning Models for Stock Momentum Trading
Implementing deep reinforcement learning (DRL) models for stock momentum trading involves several steps, including selecting a programming language, setting up a development environment, and integrating with trading platforms. In this section, we will discuss these steps and provide examples of popular libraries and frameworks for DRL model development.
Selecting a Programming Language
Python is the most popular programming language for DRL model development due to its simplicity, extensive libraries, and strong community support. Other options include R, Julia, and MATLAB, but they may not offer the same level of flexibility and scalability as Python.
Setting Up a Development Environment
To set up a development environment for DRL model development, consider using tools such as Anaconda, a free and open-source distribution of Python and R for scientific computing. Anaconda provides a comprehensive environment for DRL model development, including popular libraries like TensorFlow, PyTorch, and OpenAI Gym.
Integrating with Trading Platforms
Integrating DRL models with trading platforms requires connecting the model to data feeds and order management systems. Popular trading platforms for DRL model integration include Alpaca, QuantConnect, and Zipline. These platforms provide access to historical and real-time market data, as well as order management and execution capabilities.
Popular Libraries and Frameworks
Some of the most popular libraries and frameworks for DRL model development include TensorFlow, PyTorch, and OpenAI Gym.
- TensorFlow: An open-source library for machine learning and deep learning developed by Google. TensorFlow provides a flexible platform for DRL model development, including support for GPU acceleration and distributed computing.
- PyTorch: An open-source machine learning library developed by Facebook’s artificial-intelligence research group. PyTorch offers a dynamic computational graph and is known for its simplicity and ease of use.
- OpenAI Gym: An open-source toolkit for developing and comparing reinforcement learning algorithms. OpenAI Gym provides a standardized interface for interacting with various environments, making it easier to develop, test, and compare DRL models.
By following these steps and utilizing popular libraries and frameworks, investors can implement effective DRL models for stock momentum trading, leveraging the power of AI and machine learning to learn from data, adapt to market changes, and make informed decisions.
Training and Fine-Tuning Deep Reinforcement Learning Models for Optimal Performance
Training and fine-tuning deep reinforcement learning (DRL) models for stock momentum trading requires careful consideration of various strategies, including hyperparameter optimization, early stopping, and model ensembling. In this section, we will discuss these techniques and explain their importance in improving overall trading strategies.
Hyperparameter Optimization
Hyperparameters are parameters that are not learned from data but instead are set before training. Examples of hyperparameters include the learning rate, discount factor, and network architecture. Hyperparameter optimization involves systematically searching for the best set of hyperparameters to improve model performance. Techniques for hyperparameter optimization include grid search, random search, and Bayesian optimization.
Early Stopping
Early stopping is a technique used to prevent overfitting during model training. Overfitting occurs when a model learns the training data too well, resulting in poor generalization to new data. Early stopping involves monitoring model performance on a validation set during training and stopping the training process when the performance on the validation set starts to degrade.
Model Ensembling
Model ensembling is a technique used to improve model performance by combining the predictions of multiple models. Ensembling can reduce the variance of the predictions and improve the overall performance of the model. Techniques for model ensembling include bagging, boosting, and stacking.
Monitoring Model Performance
Monitoring model performance is critical for detecting overfitting and adjusting training parameters. Techniques for monitoring model performance include tracking the loss function, evaluating the model on a validation set, and using visualization tools.
Detecting Overfitting
Overfitting occurs when a model learns the training data too well, resulting in poor generalization to new data. Techniques for detecting overfitting include monitoring the training and validation loss, using regularization techniques, and evaluating the model on a test set.
Adjusting Training Parameters
Adjusting training parameters, such as the learning rate, batch size, and number of epochs, can improve model performance and prevent overfitting. Techniques for adjusting training parameters include learning rate schedules, gradient clipping, and weight decay.
By employing these strategies for training and fine-tuning DRL models, investors can improve model performance, reduce overfitting, and develop more effective trading strategies for stock momentum trading.
Evaluating and Comparing the Performance of Deep Reinforcement Learning Models
Evaluating and comparing the performance of deep reinforcement learning (DRL) models for stock momentum trading is crucial for selecting the best-performing model and interpreting the results. Various metrics, such as cumulative returns, risk-adjusted returns, and drawdowns, play a significant role in assessing model performance. In this section, we will discuss these metrics and provide guidance on selecting the best-performing model.
Cumulative Returns
Cumulative returns represent the total percentage change in the value of the portfolio over a given period. Cumulative returns provide a clear picture of the overall performance of the model, but they do not account for the risks taken to achieve those returns.
Risk-Adjusted Returns
Risk-adjusted returns measure the return of an investment relative to the risk taken. Common risk-adjusted return metrics include the Sharpe ratio, Sortino ratio, and Calmar ratio. These metrics provide a more comprehensive view of model performance by accounting for both returns and risks.
Drawdowns
Drawdowns represent the maximum peak-to-trough decline in the value of the portfolio during a given period. Drawdowns provide insight into the risk profile of the model and the potential losses that may occur during adverse market conditions.
Selecting the Best-Performing Model
Selecting the best-performing model involves evaluating the model’s performance using various metrics and comparing the results with other models. When selecting the best-performing model, consider the following factors:
- Consistency: A model that consistently outperforms other models across various metrics is likely to be a good choice.
- Risk-Adjusted Performance: A model that provides higher risk-adjusted returns is likely to be a better choice than a model that provides higher cumulative returns but takes on excessive risks.
- Generalization: A model that generalizes well to new data and market conditions is likely to be more robust and reliable than a model that overfits the training data.
By evaluating and comparing the performance of DRL models using various metrics, investors can select the best-performing model and develop more effective trading strategies for stock momentum trading.
Applying Deep Reinforcement Learning Models to Real-World Stock Momentum Trading Scenarios
Applying deep reinforcement learning (DRL) models to real-world stock momentum trading scenarios requires careful consideration of various factors, including risk management, position sizing, and portfolio diversification. In this section, we will discuss these factors and provide tips on monitoring model performance, updating models, and adapting to changing market conditions.
Backtesting
Backtesting involves evaluating a trading strategy on historical data to assess its performance and potential profitability. Backtesting is a crucial step in developing and refining DRL models for stock momentum trading. When backtesting DRL models, consider the following factors:
- Data Quality: Use high-quality, reliable data to ensure accurate and meaningful backtesting results.
- Simulation Realism: Simulate real-world trading conditions, including transaction costs, slippage, and market impact.
- Statistical Significance: Ensure that the backtesting results are statistically significant and not due to chance or overfitting.
Paper Trading
Paper trading involves executing trades on paper, without actually investing any money. Paper trading allows investors to test and refine their trading strategies in a risk-free environment. When paper trading DRL models, consider the following factors:
- Realistic Trading Conditions: Simulate real-world trading conditions, including transaction costs, slippage, and market impact.
- Risk Management: Implement risk management strategies, such as stop-loss orders and position sizing, to limit potential losses.
- Performance Tracking: Track the performance of the DRL model and compare it with other models and benchmarks.
Live Trading
Live trading involves executing trades with real money. When live trading DRL models, consider the following factors:
- Risk Management: Implement risk management strategies, such as stop-loss orders and position sizing, to limit potential losses.
- Monitoring: Monitor the performance of the DRL model in real-time and adjust trading parameters as needed.
- Updating: Regularly update the DRL model with new data and market conditions to ensure optimal performance.
By applying DRL models to real-world stock momentum trading scenarios and considering factors such as risk management, position sizing, and portfolio diversification, investors can develop more effective trading strategies and achieve their investment objectives.
