Unleashing the Power of Reinforcement Learning with Python
Reinforcement Learning (RL) is a cutting-edge subfield of artificial intelligence (AI) that focuses on training agents to make decisions and take actions based on maximizing cumulative rewards in a given environment. Applied Reinforcement Learning with Python. With OpenAI Gym, developers and researchers can harness the potential of RL algorithms to build intelligent systems capable of solving complex problems. This comprehensive guide will introduce you to the fundamentals of RL, Python implementation, and the powerful OpenAI Gym toolkit.

Click Image to Find Quantum Products

Getting Started: Installing Python and OpenAI Gym
To begin your journey in Applied Reinforcement Learning with Python. With OpenAI Gym, you’ll first need to install Python and set up the OpenAI Gym environment. This section provides a step-by-step guide for both Windows and macOS users.
Installing Python
For Windows:
- Visit the official Python website (https://www.python.org/downloads/windows/).
- Download the latest Python release (version 3.x.x).
- Run the installer and ensure you select the option “Add Python to PATH” during installation.
For macOS:
- Open a terminal window.
- Run the command
python3 --versionto check if Python is already installed. If not, proceed to step 3. - Run the command
brew install python3to install Homebrew and Python 3.
Setting up OpenAI Gym
After installing Python, follow these steps to set up OpenAI Gym:
- Open a terminal or command prompt and run the command
pip install gym[classic_control]to install OpenAI Gym. - Verify the installation by running the command
python -c "import gym; print(gym.__version__)">. - Install MuJoCo, a physics simulator required for some OpenAI Gym environments, by following the instructions at https://www.roboti.us/index.html.
Troubleshooting Common Installation Issues
If you encounter issues during installation, consider the following:
- Ensure you have the latest version of Python installed.
- Check for conflicts with other packages or software. You may need to use a virtual environment to isolate the

A Gentle Introduction to Reinforcement Learning Concepts
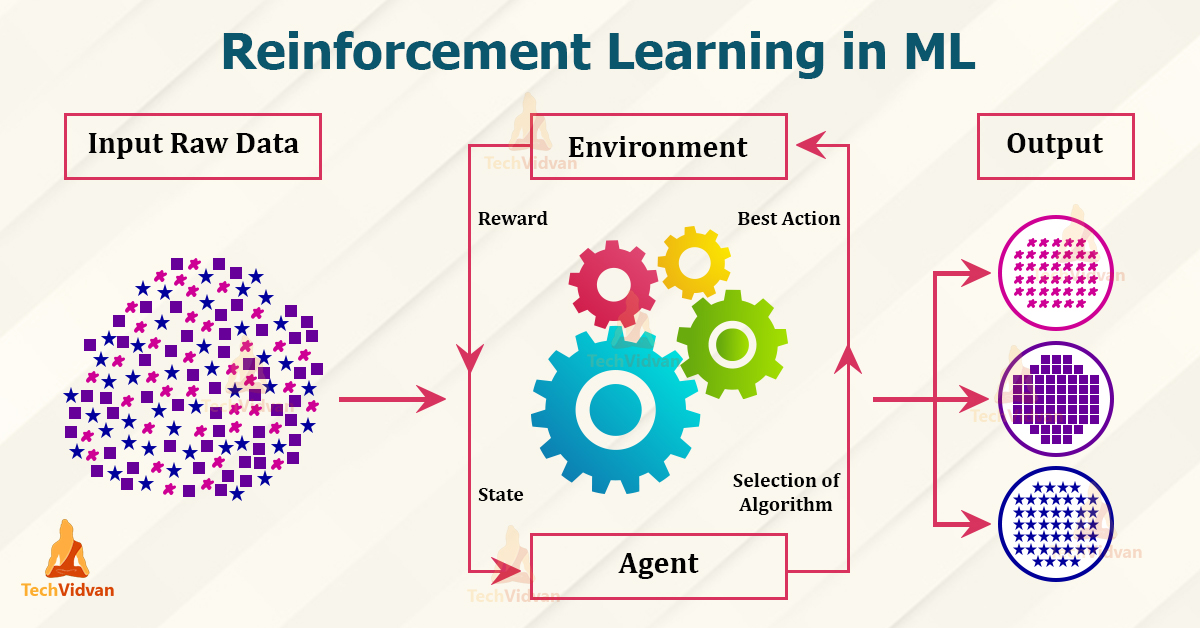
Reinforcement Learning (RL) is a subfield of Artificial Intelligence (AI) that focuses on agents learning to make decisions by interacting with their environment. The agent takes actions to achieve a goal and receives rewards or penalties based on the outcomes. By continuously learning from these rewards and penalties, the agent optimizes its decision-making process to maximize the cumulative reward.
Key Reinforcement Learning Concepts
To better understand RL, consider the following fundamental concepts:
- Agent: The entity that makes decisions and performs actions in the environment.
- Environment: The world where the agent operates, providing feedback in the form of states, rewards, and penalties.
- State: The current situation the agent encounters, represented as a set of features or variables.
- Actions: The decisions or choices made by the agent based on the current state.
- Rewards: Numeric feedback provided to the agent based on its actions, driving it to maximize the cumulative reward.
Simple Example: CartPole Environment
To illustrate these concepts, consider the CartPole environment in OpenAI Gym. The agent controls a pole attached to a cart, aiming to keep the pole upright while the cart moves along a track. The agent receives a reward of +1 for every time step it keeps the pole upright, and the episode ends when the pole falls or the cart moves off the track.
- Agent: The software controlling the cart and pole.
- Environment: The cart, track, and pole system.
- State: The position and velocity of the cart and angle and angular velocity of the pole.
- Actions: Apply a force of +1 or -1 to the cart.
- Rewards: A reward of +1 for every time step the pole remains upright.
By understanding these fundamental RL concepts and experimenting with OpenAI Gym environments, you can begin to explore the world of Applied Reinforcement Learning with Python.
Exploring OpenAI Gym: A Playground for Reinforcement Learning
OpenAI Gym is an essential component of Applied Reinforcement Learning with Python, providing a versatile platform for developing, testing, and comparing reinforcement learning algorithms. With its extensive collection of built-in environments and the ability to create custom environments, OpenAI Gym has become an indispensable resource for AI researchers and enthusiasts alike.
Built-In Environments
OpenAI Gym offers a wide variety of built-in environments, ranging from simple to complex, designed to test and compare reinforcement learning algorithms. These environments include:
- Classic Control: Simple, 2D environments, such as CartPole, Acrobot, and MountainCar, ideal for beginners.
- Algorithmic: Environments that require specific algorithms to solve, like Reversi and Rush Hour.
- Atari: Classic Atari 2600 games, such as Pong, Space Invaders, and Breakout, for more advanced RL tasks.
- MuJoCo: Physics-based environments for simulating robots and other physical systems.
Creating Custom Environments
In addition to the built-in environments, OpenAI Gym allows users to create custom environments tailored to specific use cases. To create a custom environment, users must define the following components:
- Observation Space: The set of possible states the agent can encounter.
- Action Space: The set of possible actions the agent can take.
- Reward Function: The rule for calculating rewards based on the agent’s actions.
- Reset Function: The method for resetting the environment to its initial state.
- Step Function: The method for advancing the environment by one time step and returning the new state, reward, and done flag.
Benchmarking and Comparing Algorithms
OpenAI Gym facilitates benchmarking and comparing different reinforcement learning algorithms by providing standardized environments and metrics. Users can evaluate their algorithms’ performance against pre-existing solutions and other algorithms, fostering innovation and progress in the field of reinforcement learning.
By leveraging OpenAI Gym’s features, developers can harness the power of Applied Reinforcement Learning with Python, unlocking new possibilities for AI applications and pushing the boundaries of what’s possible in the realm of artificial intelligence.
Hands-On: Implementing Basic Reinforcement Learning Algorithms with Python
To truly master Applied Reinforcement Learning with Python and OpenAI Gym, getting hands-on experience with implementing basic reinforcement learning algorithms is essential. In this section, we will guide you through implementing two fundamental algorithms: Q-Learning and SARSA.
Q-Learning
Q-Learning is a value-based reinforcement learning algorithm that aims to learn the optimal action-value function, Q\*(s, a), which represents the expected total reward for taking action a in state s and then following the optimal policy thereafter. The Q-Learning update rule is as follows:
Q(s,a) = Q(s,a) + α * (r + γ * max(Q(s', a')) - Q(s,a))Here, α is the learning rate, r is the reward, γ is the discount factor, and s’ and a’ are the next state and action, respectively. Implementing Q-Learning in Python involves initializing the Q-table, setting the learning rate and discount factor, and iterating through episodes and steps to update the Q-table.
SARSA
SARSA (State-Action-Reward-State-Action) is another value-based reinforcement learning algorithm that learns the Q-function. However, unlike Q-Learning, SARSA updates the Q-value using the current policy’s action-value function, making it an on-policy algorithm. The SARSA update rule is as follows:
Q(s,a) = Q(s,a) + α * (r + γ * Q(s', a') - Q(s,a))Here, a’ is the action taken in the next state, s’. Implementing SARSA in Python is similar to Q-Learning, with the primary difference being the selection of the next action based on the current policy instead of the greedy policy.
Training and Testing
To train and test these algorithms on OpenAI Gym environments, initialize the environment, set the number of episodes and steps, and run the learning loop. After training, test the learned policy by running it in the environment and observing the resulting rewards and actions. By implementing and experimenting with these basic reinforcement learning algorithms, you will gain a deeper understanding of Applied Reinforcement Learning with Python and OpenAI Gym.
Advanced Techniques: Deep Reinforcement Learning and Policy Gradients
As you progress in your journey of mastering Applied Reinforcement Learning with Python and OpenAI Gym, it’s essential to explore advanced techniques that can help solve more complex problems. Two such techniques are Deep Reinforcement Learning and Policy Gradients.
Deep Reinforcement Learning
Deep Reinforcement Learning combines reinforcement learning with deep learning, allowing agents to learn from raw input data, such as images or videos. This technique is particularly useful for environments with high-dimensional state spaces, where traditional reinforcement learning algorithms struggle to learn an optimal policy. Deep Reinforcement Learning has achieved remarkable results in various domains, such as playing video games, robotics, and autonomous driving.
Policy Gradients
Policy Gradients are a class of reinforcement learning algorithms that aim to optimize the policy directly, rather than learning the value function. These algorithms are particularly useful for continuous state and action spaces, where traditional value-based methods are less effective. Policy Gradients work by iteratively updating the policy in the direction of higher expected rewards. Some popular Policy Gradient algorithms include REINFORCE, Actor-Critic, and Proximal Policy Optimization (PPO).
Advantages and Real-World Applications
Deep Reinforcement Learning and Policy Gradients offer several advantages over basic reinforcement learning algorithms. They can handle high-dimensional state spaces, continuous action spaces, and complex dynamics. These advanced techniques have been successfully applied to various real-world applications, such as AlphaGo, which defeated the world champion in the game of Go, and Tesla’s Autopilot system, which uses deep reinforcement learning for autonomous driving.
Optimizing and Troubleshooting Reinforcement Learning Models
As you delve deeper into Applied Reinforcement Learning with Python and OpenAI Gym, it’s crucial to understand strategies for optimizing and troubleshooting reinforcement learning models. This section covers techniques such as hyperparameter tuning, reward shaping, and exploration vs exploitation trade-offs, providing tips for improving model performance and avoiding common pitfalls.
Hyperparameter Tuning
Hyperparameters are parameters that are not learned from the data but are set before training. Examples include the learning rate, discount factor, and network architecture. Hyperparameter tuning involves finding the optimal set of hyperparameters that yield the best performance. Techniques for hyperparameter tuning include grid search, random search, and Bayesian optimization.
Reward Shaping
Reward shaping is the process of modifying the reward function to encourage or discourage certain behaviors. A well-designed reward function can significantly improve the learning process, while a poorly designed one can lead to suboptimal policies. Techniques for reward shaping include adding auxiliary rewards, shaping rewards using potential-based methods, and using human feedback to shape rewards.
Exploration vs Exploitation Trade-offs
Exploration and exploitation are two fundamental concepts in reinforcement learning. Exploration involves trying out new actions to gather more information about the environment, while exploitation involves choosing the action with the highest expected reward. Balancing exploration and exploitation is crucial for finding the optimal policy. Techniques for balancing exploration and exploitation include epsilon-greedy, Boltzmann exploration, and Upper Confidence Bound (UCB).
Tips for Improving Model Performance
Here are some tips for improving model performance in reinforcement learning:
- Use a replay buffer to store and sample past experiences, improving sample efficiency.
- Use function approximation, such as neural networks, to generalize over state spaces.
- Use multi-agent techniques, such as independent learners or centralized critics, for complex multi-agent environments.
- Use transfer learning to leverage knowledge from pre-trained models or similar tasks.
Avoiding Common Pitfalls
Here are some common pitfalls to avoid in reinforcement learning:
- Avoid overfitting by using regularization techniques, such as L1 or L2 regularization, or early stopping.
- Avoid convergence to suboptimal policies by using techniques such as reward shaping, exploration vs exploitation trade-offs, and hyperparameter tuning.
- Avoid instability during training by using techniques such as gradient clipping, weight decay, and adaptive learning rates.
Expanding Your Skills: Further Resources and Project Ideas
As you progress in your journey of mastering Applied Reinforcement Learning with Python and OpenAI Gym, it’s essential to continue learning and applying your skills. This section provides further resources and project ideas to help you expand your knowledge and expertise.
Further Resources
Here are some valuable resources for learning reinforcement learning with Python and OpenAI Gym:
- Spinning Up in Deep RL: A comprehensive guide to deep reinforcement learning, created by OpenAI.
- Deep Reinforcement Learning Hands-On with Python and OpenAI Gym: A practical book for learning deep reinforcement learning with Python and OpenAI Gym.
- Reinforcement Learning Specialization: A series of courses on reinforcement learning, created by the University of Alberta and offered on Coursera.
Project Ideas
Here are some project ideas that can help you apply your newfound skills in reinforcement learning with Python and OpenAI Gym:
- Create a custom environment that simulates a real-world problem, such as optimizing a manufacturing process or managing a supply chain.
- Implement and compare different reinforcement learning algorithms, such as Q-Learning, SARSA, and Deep Q-Networks, on various OpenAI Gym environments.
- Experiment with reward shaping and hyperparameter tuning to improve the performance of reinforcement learning models.
- Implement multi-agent reinforcement learning techniques, such as independent learners or centralized critics, for complex multi-agent environments.
- Use transfer learning to leverage knowledge from pre-trained models or similar tasks in reinforcement learning.
Remember to share your projects and experiences with the community, and don’t hesitate to seek feedback and support from fellow learners and experts. By continuing to learn and apply your skills, you can become a proficient practitioner of Applied Reinforcement Learning with Python and OpenAI Gym.