Introduction to Reinforcement Learning and Actor-Critic Methods
Reinforcement learning (RL) is a subfield of machine learning that focuses on training agents to make decisions and take actions within an environment to maximize cumulative rewards. In RL, an agent learns by interacting with its environment, receiving feedback in the form of rewards or penalties, and adjusting its behavior accordingly. Actor-critic based algorithms are a class of RL methods that combine the benefits of both value-based and policy-based approaches. These algorithms consist of two main components: the actor and the critic. The actor is responsible for selecting actions based on the current policy, while the critic evaluates the value of the chosen actions and provides feedback to the actor. This interaction allows actor-critic methods to strike a balance between exploration (trying new actions) and exploitation (choosing the best action based on current knowledge), leading to more efficient learning and better performance compared to other RL techniques.
Actor-critic based algorithms have gained popularity due to their ability to handle complex, high-dimensional problems and continuous action spaces. They have been successfully applied to various domains, including robotics, gaming, and autonomous systems, demonstrating their potential for real-world impact.

Click Image to Find Quantum Products
Key Components of Actor-Critic Based Algorithms
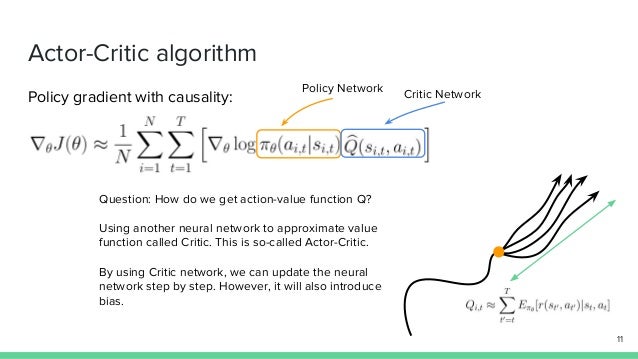
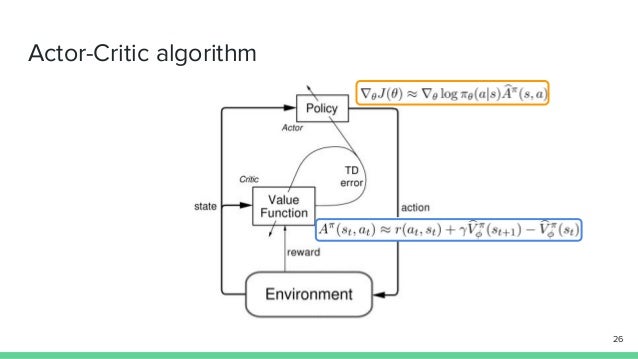
Actor-critic based algorithms are a type of reinforcement learning (RL) method that consist of two main components: the actor and the critic. These components work together to optimize the agent’s policy and maximize the expected cumulative reward. The actor is responsible for selecting actions based on the current policy. It learns to map states to actions, updating the policy as it gathers more experience and receives feedback from the environment. The actor’s primary goal is to improve the quality of the actions it selects, focusing on exploration and exploitation trade-offs.
The critic, on the other hand, evaluates the value of the actions taken by the actor. It estimates the expected return of a given state-action pair, providing feedback to the actor about the quality of its choices. The critic’s primary goal is to improve the accuracy of the value estimation, allowing the actor to make better decisions.
The interaction between the actor and the critic offers several advantages over other RL methods. By combining the benefits of both value-based and policy-based approaches, actor-critic algorithms can achieve more efficient learning, better convergence, and improved performance in complex, high-dimensional problems.
Actor-critic methods also benefit from reduced variance compared to policy-based methods, as they rely on value estimates provided by the critic. This variance reduction leads to more stable learning and smoother convergence. Additionally, actor-critic algorithms can handle continuous action spaces, making them suitable for a wide range of applications.
In summary, the actor and critic components of actor-critic based algorithms work together to optimize the agent’s policy and maximize the expected cumulative reward. The actor selects actions, while the critic evaluates their quality. This interaction results in efficient learning, better convergence, and improved performance in complex RL problems.

Popular Actor-Critic Based Algorithms
Actor-critic based algorithms have gained popularity in the reinforcement learning (RL) community due to their efficiency and performance. Some popular actor-critic based algorithms include Advantage Actor-Critic (A2C), Asynchronous Advantage Actor-Critic (A3C), and Proximal Policy Optimization (PPO). Advantage Actor-Critic (A2C) is a synchronous, deterministic variant of the Asynchronous Advantage Actor-Critic (A3C) algorithm. A2C uses multiple parallel agents to interact with the environment and share gradients during training. This approach leads to more stable learning and better sample efficiency compared to traditional policy gradient methods. A2C’s primary advantage is its ability to reduce the variance of the policy gradient estimate, leading to faster convergence and improved performance.
Asynchronous Advantage Actor-Critic (A3C) is an extension of the standard actor-critic method that utilizes multiple parallel agents to learn from the environment. A3C’s asynchronous nature allows for better exploration and more efficient use of computational resources. By sharing gradients across agents, A3C can reduce the variance of the policy gradient estimate and improve overall learning performance. However, A3C may suffer from slower convergence and increased communication overhead compared to A2C.
Proximal Policy Optimization (PPO) is a policy optimization method that strikes a balance between sample complexity and ease of implementation. PPO introduces a surrogate objective function that maintains a trust region around the current policy, ensuring that the new policy does not deviate too far from the previous one. This approach leads to more stable learning and better sample efficiency compared to traditional policy gradient methods. PPO’s primary advantage is its ability to handle complex, high-dimensional action spaces and its robustness to hyperparameter tuning.
In summary, popular actor-critic based algorithms such as A2C, A3C, and PPO offer various features and benefits for RL applications. A2C provides a synchronous, deterministic approach with reduced variance, while A3C offers asynchronous learning with better exploration. PPO introduces a surrogate objective function to maintain a trust region, ensuring stable learning and better sample efficiency. These algorithms demonstrate the versatility and effectiveness of actor-critic based methods in solving complex RL problems.

Applications of Actor-Critic Based Algorithms
Actor-critic based algorithms have found their way into various real-world applications, demonstrating their effectiveness and versatility. These applications span across multiple domains, including robotics, gaming, and autonomous systems. Robotics: Actor-critic based algorithms have been used to control robotic manipulators and mobile robots. For instance, researchers have applied these methods to robotic grasping tasks, where a robot learns to adjust its grip based on the object’s properties and the environment’s constraints. Additionally, actor-critic based algorithms have been used to teach robots how to navigate complex environments, such as warehouses or construction sites, by optimizing their movement and decision-making processes.
Gaming: The gaming industry has also benefited from actor-critic based algorithms. These methods have been used to train agents to play complex video games, such as Atari or Go, by learning optimal policies and strategies. For example, Google’s DeepMind used actor-critic based algorithms to train an agent to play the game of Go at a superhuman level, surpassing the performance of professional human players.
Autonomous Systems: Actor-critic based algorithms have been applied to autonomous systems, such as self-driving cars, to optimize their decision-making processes. These algorithms can help autonomous vehicles navigate complex traffic scenarios, predict other drivers’ behavior, and make safe driving decisions. Moreover, actor-critic based algorithms can be used to optimize energy consumption and route planning, leading to more efficient and eco-friendly transportation systems.
In summary, actor-critic based algorithms have shown promising results in various real-world applications, including robotics, gaming, and autonomous systems. By optimizing agents’ decision-making processes and learning from the environment, these algorithms can lead to more efficient, safe, and intelligent systems. As the field continues to evolve, we can expect to see even more innovative applications of actor-critic based algorithms in the future.
https://www.youtube.com/watch?v=n6K8FfqQ7ds
How to Implement Actor-Critic Based Algorithms
Implementing actor-critic based algorithms involves several essential components, including policy gradients, value functions, and exploration strategies. Here’s a step-by-step guide to help you understand the process.
Step 1: Define the Environment and State Space: The first step is to define the environment and state space. The environment is the world where the agent operates, and the state space represents the set of possible states the agent can be in.
Step 2: Define the Action Space: The action space is the set of possible actions the agent can take in each state. The action space can be discrete or continuous, depending on the problem.
Step 3: Define the Reward Function: The reward function defines the feedback the agent receives from the environment after taking an action. The goal of the agent is to maximize the cumulative reward over time.
Step 4: Initialize the Actor and Critic Networks: The actor network maps states to actions, while the critic network maps state-action pairs to a value function. Initialize both networks with random weights.
Step 5: Collect Experience and Train the Critic: Use the actor network to select actions based on the current state. Collect experience by interacting with the environment and observing the resulting states, actions, rewards, and next states. Use this experience to train the critic network by minimizing the mean-squared error between the predicted value and the true value.
Step 6: Train the Actor: Use the trained critic network to evaluate the actor network’s performance. Compute the policy gradient, which represents the direction of steepest ascent in the policy space. Update the actor network’s weights using the policy gradient and a learning rate.
Step 7: Implement Exploration Strategies: Implement exploration strategies, such as epsilon-greedy or entropy-based exploration, to encourage the agent to explore the environment and avoid getting stuck in local optima.
Step 8: Monitor Performance Metrics: Monitor performance metrics, such as the average reward per episode or the success rate, to evaluate the effectiveness of the algorithm.
Step 9: Fine-Tune and Optimize: Fine-tune and optimize the algorithm by adjusting hyperparameters, such as the learning rate, exploration rate, or network architecture.
In summary, implementing actor-critic based algorithms involves defining the environment, state space, action space, and reward function. It also involves initializing the actor and critic networks, collecting experience, training the critic and actor networks, implementing exploration strategies, monitoring performance metrics, and fine-tuning and optimizing the algorithm. By following these steps, you can create an effective actor-critic based algorithm that can solve complex reinforcement learning problems.
Tuning and Optimizing Actor-Critic Based Algorithms
Tuning and optimizing actor-critic based algorithms is crucial to achieving optimal performance. Here are some techniques to help you achieve this. Hyperparameter Optimization: Hyperparameters are parameters that are not learned from the data but are set before training. Examples include the learning rate, batch size, and number of hidden layers. Hyperparameter optimization involves selecting the best set of hyperparameters to minimize the loss function. Techniques for hyperparameter optimization include grid search, random search, and Bayesian optimization.
Learning Rate Scheduling: The learning rate is a hyperparameter that controls the step size at each iteration of the training process. Selecting an appropriate learning rate is crucial to achieving optimal performance. Learning rate scheduling involves adjusting the learning rate during training to improve convergence. Techniques for learning rate scheduling include step decay, exponential decay, and 1/t decay.
Regularization Methods: Regularization methods are used to prevent overfitting and improve generalization. Examples include L1 and L2 regularization, dropout, and early stopping. Regularization methods can be applied to both the actor and critic networks to improve performance.
Monitoring Performance Metrics: Monitoring performance metrics, such as the average reward per episode or the success rate, is crucial to evaluating the effectiveness of the algorithm. Performance metrics can be used to diagnose convergence issues, identify hyperparameters that need tuning, and compare different algorithms.
Adapting the Learning Process: Adapting the learning process involves adjusting the algorithm during training to improve performance. Examples include using experience replay, prioritized experience replay, and entropy-based exploration. Adapting the learning process can help improve convergence, reduce variance, and encourage exploration.
In summary, tuning and optimizing actor-critic based algorithms involves hyperparameter optimization, learning rate scheduling, regularization methods, monitoring performance metrics, and adapting the learning process. By employing these techniques, you can improve the performance of your actor-critic based algorithm and achieve optimal results. It’s important to note that tuning and optimizing actor-critic based algorithms can be a time-consuming and iterative process, but the results are worth the effort.
Challenges and Limitations of Actor-Critic Based Algorithms
Despite their advantages, actor-critic based algorithms face several challenges and limitations. Here are some of the most significant ones and potential solutions.
Convergence Issues: Actor-critic based algorithms can suffer from convergence issues, especially when using function approximators like neural networks. This is because the actor and critic networks are updated simultaneously, which can lead to instability. One potential solution is to use techniques like experience replay and target networks to stabilize the learning process.
Sensitivity to Hyperparameters: Actor-critic based algorithms can be sensitive to hyperparameters, such as the learning rate, discount factor, and entropy regularization coefficient. Selecting appropriate hyperparameters can be challenging, and inappropriate hyperparameters can lead to poor performance. One potential solution is to use hyperparameter optimization techniques like grid search, random search, and Bayesian optimization.
Need for Extensive Computational Resources: Actor-critic based algorithms can require extensive computational resources, especially when using large neural networks. This can make them impractical for some applications. One potential solution is to use techniques like model compression and parallelization to reduce computational requirements.
Lack of Exploration: Actor-critic based algorithms can suffer from a lack of exploration, especially when using function approximators like neural networks. This can lead to poor performance and convergence issues. One potential solution is to use exploration strategies like entropy-based exploration and curiosity-driven exploration.
Difficulty in Handling Delayed Rewards: Actor-critic based algorithms can have difficulty handling delayed rewards, which can lead to poor performance. One potential solution is to use techniques like reward shaping and temporal difference methods.
In summary, actor-critic based algorithms face challenges and limitations, including convergence issues, sensitivity to hyperparameters, the need for extensive computational resources, lack of exploration, and difficulty in handling delayed rewards. Potential solutions include using experience replay, target networks, hyperparameter optimization techniques, model compression, parallelization, exploration strategies, reward shaping, and temporal difference methods. By employing these techniques, you can overcome the challenges and limitations of actor-critic based algorithms and achieve optimal results.
Future Directions and Research in Actor-Critic Based Algorithms
Actor-critic based algorithms have shown great promise in various applications, and researchers continue to explore new ways to improve their performance and applicability. Here are some emerging trends and future research directions in actor-critic based algorithms.
Multi-Agent Systems: Multi-agent systems involve multiple agents interacting with each other in a shared environment. Actor-critic based algorithms can be used to train individual agents in a multi-agent system, enabling them to learn optimal policies in a decentralized manner. Future research in this area could focus on developing scalable and efficient actor-critic based algorithms for multi-agent systems.
Continuous Control: Continuous control problems involve optimizing policies over continuous action spaces. Actor-critic based algorithms are well-suited for continuous control problems, as they can learn policies that map states to continuous actions. Future research in this area could focus on developing more efficient and effective actor-critic based algorithms for continuous control problems.
Transfer Learning: Transfer learning involves using knowledge gained from one task to improve performance on another related task. Actor-critic based algorithms can be used for transfer learning, as they can learn policies that generalize well to new tasks. Future research in this area could focus on developing actor-critic based algorithms that can effectively transfer knowledge across tasks.
Emerging Applications: Actor-critic based algorithms have shown great promise in various applications, including robotics, gaming, and autonomous systems. Future research could focus on exploring new applications of actor-critic based algorithms, such as natural language processing, computer vision, and healthcare.
In summary, actor-critic based algorithms continue to be an active area of research, with emerging trends in multi-agent systems, continuous control, and transfer learning. Future research could also focus on exploring new applications of actor-critic based algorithms in various fields. By continuing to innovate and improve actor-critic based algorithms, researchers can unlock their full potential and enable new applications and advancements in the field.
