An In-depth Examination of Reinforcement Learning’s Q-Learning and Its Distinguished Offshoots
Reinforcement Learning (RL) is a significant branch of artificial intelligence (AI) that focuses on training agents to make decisions and take actions based on their environment to maximize cumulative rewards. Among the various RL algorithms, Q-Learning has emerged as a fundamental and influential technique. This article delves into the concept of Q-Learning and its renowned variants, emphasizing their implementation using Python.

Click Image to Find Quantum Products
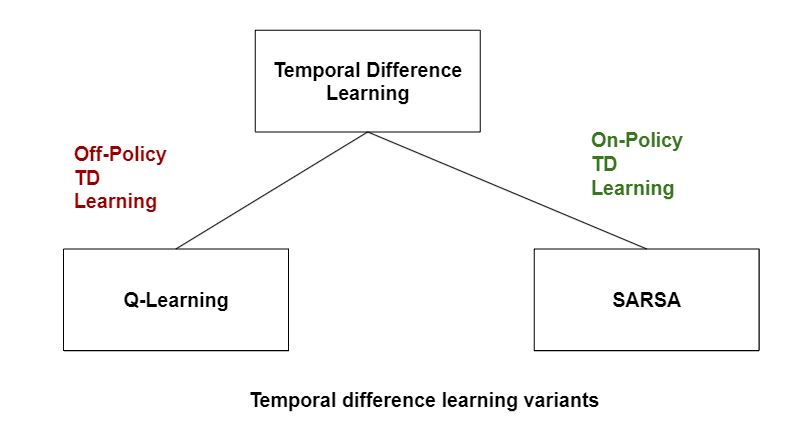
Q-Learning: The Genesis of Temporal Difference (TD) Learning
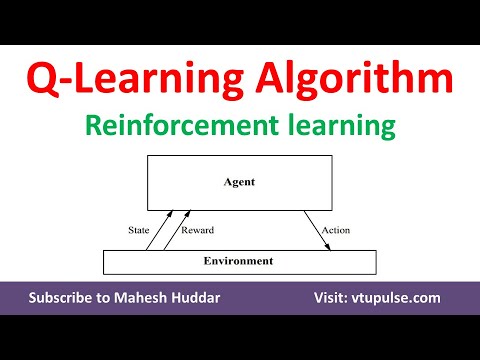
Q-Learning is a pivotal algorithm in reinforcement learning, originating from the Temporal Difference (TD) learning framework. TD learning combines Monte Carlo methods and dynamic programming, enabling agents to learn directly from experience without requiring a complete model of the environment. Q-Learning specifically focuses on estimating the action-value function, which represents the expected cumulative reward of taking a particular action in a given state.
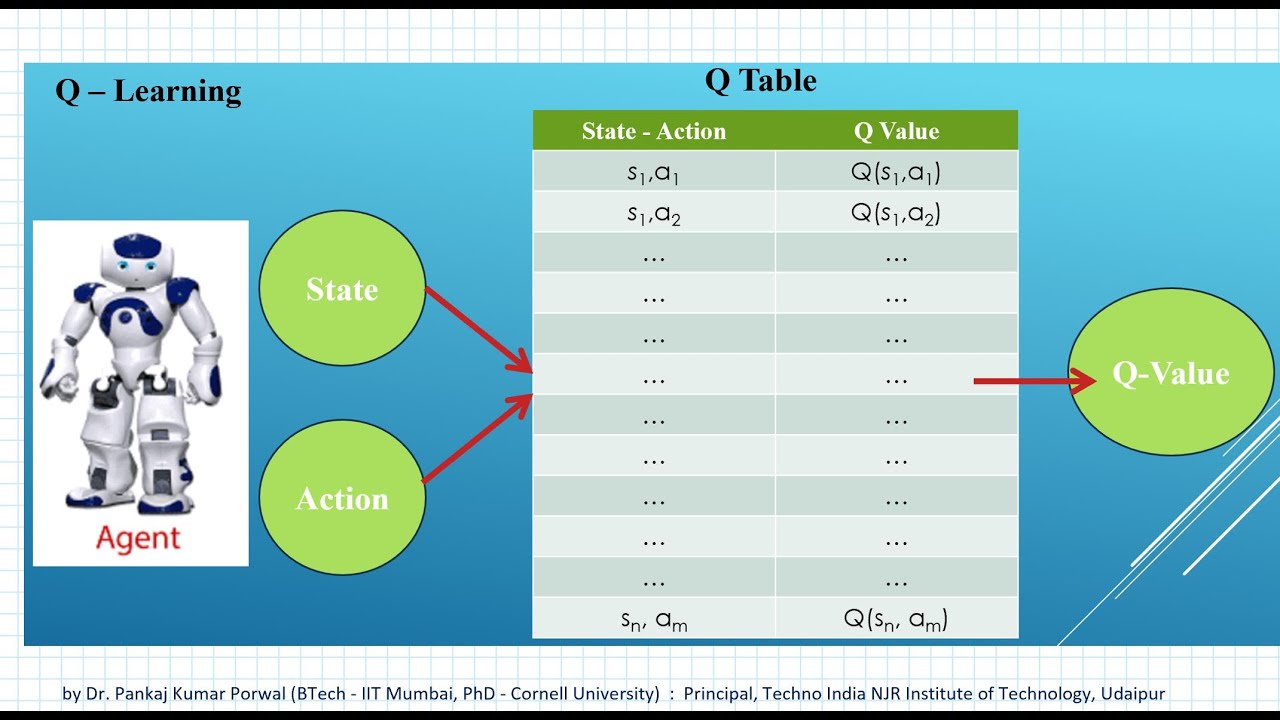
The core principle of Q-Learning revolves around the Q-table, a data structure that stores the estimated action-value function. Each entry in the Q-table corresponds to a state-action pair, with the value updated iteratively based on the observed rewards and the maximum expected future rewards of the subsequent states. This process is known as Q-value iteration or Q-learning.
Action selection strategies play a crucial role in Q-Learning, influencing the exploration-exploitation trade-off during the learning process. Common strategies include:
- Epsilon-greedy: With probability (1 – epsilon), the agent selects the action with the highest Q-value for the current state. Otherwise, it chooses a random action with probability epsilon, promoting exploration.
- Boltzmann exploration: The agent selects actions according to a probability distribution that decays exponentially with the Q-values, allowing for a smooth transition between exploration and exploitation.
- Upper Confidence Bound (UCB): The agent balances exploration and exploitation by favoring actions with high uncertainty, encouraging the exploration of less-visited state-action pairs.
Python has become a popular language for implementing Q-Learning and its variants, thanks to its simplicity, versatility, and extensive library support, such as NumPy, Pandas, and Matplotlib. These libraries facilitate efficient array operations, data manipulation, and visualization, enabling researchers and developers to focus on the core RL algorithms.

Variants of Q-Learning: Expanding the Horizons of TD Learning
Q-Learning, as a fundamental algorithm in reinforcement learning, has inspired numerous variants that build upon its core principles. These offshoots often address specific challenges or limitations of traditional Q-Learning, enhancing its performance and applicability in various domains. Python has been instrumental in implementing these Q-Learning variants, thanks to its extensive library support and user-friendly syntax.
One of the most prominent Q-Learning variants is the Deep Q-Network (DQN), which combines Q-Learning with deep neural networks. DQN overcomes the challenge of large state spaces in Q-Learning by approximating the action-value function using a deep neural network. This approach enables DQN to handle high-dimensional inputs, such as raw images, making it suitable for complex environments like Atari games. The use of experience replay and target networks further stabilizes the learning process, reducing the correlation between consecutive samples and smoothing the Q-value updates.
Double Deep Q-Network (Double DQN) is another variant that addresses the overestimation issue in DQN. Overestimation can occur when the maximum Q-value is used to select and evaluate actions, leading to suboptimal policies. Double DQN decouples action selection and evaluation by using two separate neural networks, one for each task. This separation reduces the likelihood of overestimation, improving the overall performance of DQN.
Dueling Double Deep Q-Network (Dueling DQN) introduces an additional architecture to further improve DQN’s performance. Dueling DQN splits the action-value function into two components: the state-value function and the advantage function. The state-value function estimates the expected cumulative reward of being in a given state, while the advantage function evaluates the relative advantage of taking a specific action in that state. By combining these two components, Dueling DQN can better capture the nuances of complex environments, leading to more informed action selections.
Python’s flexibility and rich library ecosystem, such as TensorFlow and PyTorch, have been instrumental in the development and implementation of these Q-Learning variants. These libraries provide efficient tools for building, training, and fine-tuning deep neural networks, enabling researchers and developers to focus on the unique aspects of each Q-Learning variant.
How to Implement Q-Learning and Its Variants Using Python
Implementing Q-Learning and its variants using Python is a straightforward process, thanks to the language’s simplicity and extensive library support. This section will provide a step-by-step guide on how to apply Q-Learning and its popular variants, such as Deep Q-Network (DQN), Double DQN, and Dueling DQN, using Python.
To begin, it is essential to understand the primary components of Q-Learning: the Q-table, reward, and action selection strategies. The Q-table is a table that stores the expected cumulative rewards for each state-action pair. Rewards are numerical values that the agent receives upon taking a specific action in a given state. Action selection strategies, such as ε-greedy, help balance exploration and exploitation during the learning process.
For traditional Q-Learning, Python provides several libraries, such as NumPy and Pandas, to manage and manipulate the Q-table. The implementation involves initializing the Q-table, setting the learning rate and discount factor, and iterating through episodes and steps to update the Q-values based on the observed rewards and chosen actions. Listing 1 demonstrates a simple Q-Learning implementation in Python:
import numpy as np def q_learning(env, n_episodes, learning_rate, discount_factor):
Q = np.zeros([env.observation_space.n, env.action_space.n])
for episode in range(n_episodes):
state = env.reset()
for step in range(1000):
action = choose_action(Q, state, learning_rate, discount_factor, 0.1)
next_state, reward, done, _ = env.step(action)
Q[state, action] = update_q_value(Q, state, action, reward, next_state, learning_rate, discount_factor)
if done:
break
state = next_state
return Q
Next, we will discuss implementing Q-Learning variants using Python. Deep Q-Network (DQN) combines Q-Learning with deep neural networks to handle large state spaces. Python libraries like TensorFlow and Keras simplify the creation and training of deep neural networks. Listing 2 shows a simplified DQN implementation using TensorFlow:
import tensorflow as tf def build_dqn(state_dim, action_dim):
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(64, activation='relu', input_shape=(state_dim,)))
model.add(tf.keras.layers.Dense(64, activation='relu'))
model.add(tf.keras.layers.Dense(action_dim))
return model
def dqn_learning(env, n_episodes, learning_rate, discount_factor):
model = build_dqn(env.observation_space.n, env.action_space.n)
for episode in range(n_episodes):
state = env.reset()
for step in range(1000):
action = choose_action(model, state, learning_rate, discount_factor, 0.1)
next_state, reward, done, _ = env.step(action)
with tf.GradientTape() as tape:
next_action = tf.argmax(model(next_state), axis=1)
target_q = reward + discount_factor * tf.reduce_sum(model(next_state) * tf.one_hot(next_action, env.action_space.n), axis=1)
loss = tf.reduce_mean(tf.square(target_q - model(state)))
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if done:
break
state = next_state
Implementing Double DQN and Dueling DQN follows a similar pattern, with minor modifications to the neural network architecture and action selection strategies. Python’s flexibility and rich library ecosystem enable seamless integration of these Q-Learning variants, making them accessible to both beginners and experienced developers.
Practical Applications of Q-Learning and Its Variants
Reinforcement learning, a significant branch of artificial intelligence, has garnered considerable attention for its potential to create intelligent systems that can learn from interactions with their environment. Among reinforcement learning algorithms, Q-Learning and its variants have emerged as powerful tools for solving complex problems. This article will explore the real-world applications of Q-Learning and its variants, such as Deep Q-Network (DQN), Double DQN, and Dueling DQN, highlighting their success stories and case studies.
In the realm of gaming, Q-Learning and its variants have achieved remarkable results. For instance, Google’s DeepMind utilized DQN to develop an agent capable of mastering Atari games at a superhuman level. By combining deep neural networks with Q-Learning, the agent learned to interpret raw pixels and make informed decisions, demonstrating the potential of these algorithms in complex decision-making tasks.
Robotics is another area where Q-Learning and its variants have shown promising applications. Researchers have employed these algorithms to teach robots how to navigate and manipulate objects in their environment. For example, a team from the University of Washington used DQN to train a robotic arm to perform complex tasks, such as stacking blocks and screwing screws, by learning from raw sensory inputs.
Resource management is a critical application of Q-Learning and its variants. In this context, these algorithms have been used to optimize energy consumption, traffic signal control, and communication networks. For instance, a study from the University of Southern California utilized DQN to manage data centers more efficiently, reducing energy costs and carbon emissions.
Autonomous vehicles represent another significant application of Q-Learning and its variants. Companies like Tesla, Waymo, and NVIDIA have integrated reinforcement learning techniques into their autonomous driving systems to improve decision-making and navigation. By continuously learning from real-world data, these systems can adapt to new scenarios and enhance safety.
In summary, Q-Learning and its variants have proven to be valuable tools in various real-world applications, including gaming, robotics, resource management, and autonomous vehicles. By enabling intelligent systems to learn from interactions with their environment, these algorithms have the potential to revolutionize numerous industries and improve the quality of life for people worldwide.

Mastering Q-Learning and Its Renowned Variants with Python
An In-depth Examination of Reinforcement Learning’s Q-Learning and Its Distinguished Offshoots
Reinforcement learning is a significant branch of artificial intelligence, with Q-Learning being a crucial algorithm at its core. Python, a versatile and widely-used programming language, offers an ideal platform for implementing Q-Learning and its variants. This article explores the fundamental concepts of Q-Learning, its variants, and their practical applications, emphasizing the role of Python in their implementation.
Q-Learning: The Genesis of Temporal Difference (TD) Learning
Q-Learning, a central algorithm in reinforcement learning, forms the foundation of temporal difference (TD) learning. It relies on a Q-table to estimate the expected return for each state-action pair, using action selection strategies such as ε-greedy or softmax. By iteratively updating the Q-table based on the observed rewards and subsequent states, Q-Learning converges to an optimal policy given sufficient time and resources.
Variants of Q-Learning: Expanding the Horizons of TD Learning
Deep Q-Network (DQN), Double DQN, and Dueling DQN are prominent Q-Learning variants that have advanced the field of reinforcement learning. These algorithms employ deep neural networks to approximate the Q-value function, enabling them to handle high-dimensional state spaces and large action sets. While DQN is prone to overestimation, Double DQN decouples the action selection and value estimation processes to reduce this bias. Dueling DQN further improves DQN by separately estimating the state-value and advantage functions, enhancing its ability to generalize and learn optimal policies.
How to Implement Q-Learning and Its Variants Using Python
Implementing Q-Learning and its variants in Python involves several steps, including setting up the environment, defining the Q-table or neural network architecture, selecting action selection strategies, and updating the Q-values based on the observed rewards and subsequent states. Libraries such as TensorFlow, PyTorch, NumPy, and SciPy can be utilized to streamline the implementation process.
Practical Applications of Q-Learning and Its Variants
Q-Learning and its variants have been successfully applied in various domains, including gaming, robotics, resource management, and navigation. These algorithms have demonstrated their ability to learn optimal policies, adapt to changing environments, and make intelligent decisions, contributing to advancements in artificial intelligence and related fields.
Comparative Analysis: Q-Learning vs. Its Notable Variants
Q-Learning and its variants each have unique strengths, weaknesses, and applicability. Traditional Q-Learning is well-suited for low-dimensional problems, while DQN, Double DQN, and Dueling DQN excel in high-dimensional state spaces and large action sets. Considering the problem’s complexity, state and action space dimensionality, and computational resources is crucial when selecting the most appropriate Q-Learning algorithm.
Future Perspectives: Advancements and Innovations in Q-Learning
Emerging trends in Q-Learning include integrating machine learning techniques, addressing current challenges, and exploring potential future developments. These advancements aim to further enhance the performance, efficiency, and applicability of Q-Learning and its variants, driving innovation and progress in reinforcement learning and artificial intelligence.
Conclusion: The Pivotal Role of Q-Learning in Reinforcement Learning
Q-Learning and its variants play a pivotal role in reinforcement learning, offering a range of solutions for various problems. By understanding their unique features, strengths, and weaknesses, developers can make informed decisions when selecting the most suitable algorithm for their projects. Utilizing the power of python, these algorithms can be efficiently implemented and integrated into a wide array of applications, driving innovation and progress in the field of artificial intelligence.

Future Perspectives: Advancements and Innovations in Q-Learning
The field of reinforcement learning, particularly Q-Learning and its variants, continues to evolve and expand, offering exciting opportunities for advancements and innovations. By integrating machine learning techniques and addressing current challenges, Q-Learning is poised for even greater impact in the coming years.
One promising area of development is the integration of deep learning techniques with Q-Learning, leading to the creation of algorithms such as Deep Q-Network (DQN), Double DQN, and Dueling DQN. These hybrid models combine the strengths of both reinforcement learning and deep learning, enabling them to handle complex, high-dimensional environments that would be challenging for traditional Q-Learning methods.
Another area of focus is addressing the exploration-exploitation dilemma, a common challenge in reinforcement learning where agents must balance between exploring new actions and exploiting the knowledge they have already gained. Recent research has explored the use of curiosity-driven exploration, where agents are motivated to explore states with high uncertainty or novelty, potentially leading to more efficient learning and decision-making.
Furthermore, the development of scalable and efficient algorithms remains a crucial aspect of Q-Learning research. As environments become increasingly complex, traditional Q-Learning methods may struggle to maintain optimal performance. By refining action selection strategies, reward functions, and Q-table representations, researchers aim to create Q-Learning algorithms that can effectively scale to handle large, intricate environments.
In conclusion, Q-Learning and its variants have proven to be invaluable tools in the realm of reinforcement learning, enabling artificial intelligence systems to learn and adapt through experience. As the field continues to advance, we can expect to see even more sophisticated Q-Learning algorithms that leverage machine learning techniques, curiosity-driven exploration, and scalable architectures. These innovations will further solidify the pivotal role of Q-Learning in artificial intelligence and related fields, offering exciting opportunities for researchers and practitioners alike.
As you delve into the world of Q-Learning and its variants, consider the potential of these algorithms to transform various industries, from gaming and robotics to resource management and beyond. Embrace the power of Python to implement and experiment with these cutting-edge techniques, and contribute to the ongoing evolution of reinforcement learning.
With its solid foundation in Q-Learning and a promising future filled with advancements and innovations, the field of reinforcement learning stands as a testament to the limitless potential of artificial intelligence. By mastering Q-Learning and its variants, you position yourself at the forefront of this exciting discipline, ready to explore, learn, and create in a world of endless possibilities.
Now that you have been introduced to the fundamental concepts, variants, and applications of Q-Learning, as well as its role in shaping the future of reinforcement learning, it’s time to take the next step. Explore the world of Q-Learning and its variants, and apply your newfound knowledge using Python. The journey ahead is filled with learning, experimentation, and discovery, and the rewards are well worth the effort.
Remember, the world of reinforcement learning is constantly evolving, and there’s always more to learn and discover. Stay informed about the latest advancements and innovations, and continue to refine your skills in Q-Learning and Python. By doing so, you’ll be well-equipped to contribute to the ongoing development of reinforcement learning and artificial intelligence, driving the field forward and unlocking new potential for generations to come.
Conclusion: The Pivotal Role of Q-Learning in Reinforcement Learning
Throughout this article, we have explored the concept of Q-Learning and its renowned variants, emphasizing their significance in the realm of reinforcement learning and artificial intelligence. Leveraging the power of Python, we have delved into the implementation of these algorithms, demonstrating their potential to transform various industries, from gaming and robotics to resource management and beyond.
Q-Learning, as a fundamental algorithm in temporal difference learning, has laid the groundwork for numerous advancements and innovations. Its variants, such as Deep Q-Network (DQN), Double DQN, and Dueling DQN, have expanded the horizons of reinforcement learning, addressing challenges and improving performance in complex environments.
By following the step-by-step guide provided in this article, readers have gained insights into implementing Q-Learning and its variants using Python, complete with essential libraries and functions. Real-world applications of these algorithms have been discussed, sharing success stories and case studies that highlight their effectiveness.
In comparative analysis, Q-Learning has been juxtaposed with its popular variants, shedding light on their strengths, weaknesses, and suitability for different scenarios. As we look to the future, emerging trends and advancements in Q-Learning promise to further solidify its pivotal role in reinforcement learning, with potential developments in integrating machine learning techniques and addressing current challenges.
In conclusion, mastering Q-Learning and its variants is an essential step for those seeking to explore, learn, and create in the world of reinforcement learning. By applying these algorithms using Python, practitioners and researchers can contribute to the ongoing evolution of artificial intelligence, driving the field forward and unlocking new potential for generations to come.